
TinyKV Course: RaftStore执行流程
Overview
在前一节我们描述了raftstore的结构,一个raftstore可以将其看作是由ticker module, storage module, raft module等几个部分构成。在之前我们已经解析了其中的ticker module和storage module的代码,接下来我们将关注raft module这一核心部分,重点关注整个raft store结构体是怎样在外部消息的驱动下执行起来的。
首先我们回顾一下整个raftstore的结构示意图:

我们可以看到raftmodule的核心组成部分是router, peer, raftworker等几个结构体。其中peer代表了运行在该节点上的一个raft instance,它是对raft算法模块的RawNode的一层封装。RaftWorker是驱动整个系统状态前进的核心,可以将其理解为一个永远执行下去的线程。
Raft Encapsulation: raft peer
peer是对一个raft对象的封装,multi-raft中一个物理节点需要运行多个raft instance,而这些raft instance的状态必须相互隔离,peer就是对这种关系的一个封装。一个peer包含了对raft算法模块的封装:raft.RawNode, 对raft的存储模块的集成,以及cluster membership change等操作的集成。一个peer包含了以下结构:
type peer struct {
ticker *ticker
// Instance of the Raft module
RaftGroup *raft.RawNode
// The peer storage for the Raft module
peerStorage *PeerStorage
// Record the meta information of the peer
Meta *metapb.Peer
regionId uint64
// Tag which is useful for printing log
Tag string
// Record the callback of the proposals
// (Used in 2B)
proposals []*proposal
// Index of last scheduled compacted raft log.
// (Used in 2C)
LastCompactedIdx uint64
peerCache map[uint64]*metapb.Peer
PeersStartPendingTime map[uint64]time.Time
stopped bool
SizeDiffHint uint64
ApproximateSize *uint64
}其中LastCompactedIdx是与raft的log compaction相关的内容,peerCache, PeerStartPendingTime是与cluster membership change等相关的内容。目前我们重点关注的内容在普通的raft算法执行流程,所以暂时省略这些内容,而在正常的raft流程执行过程中比较重要的内容则是raft.RawNode和PeerStorage。
raftstore process
raftstore bootsup
raftstore的启动函数是raftstore::start(), 而raftstore并没有一个类似于newRaftStore之类的函数能用于创建一个有意义的raftstore对象,因此这个start函数同时具有创建raftstore对象,初始化以及运行raftstore实例的功能。整个raftstore::start的执行流示意图如下所示:
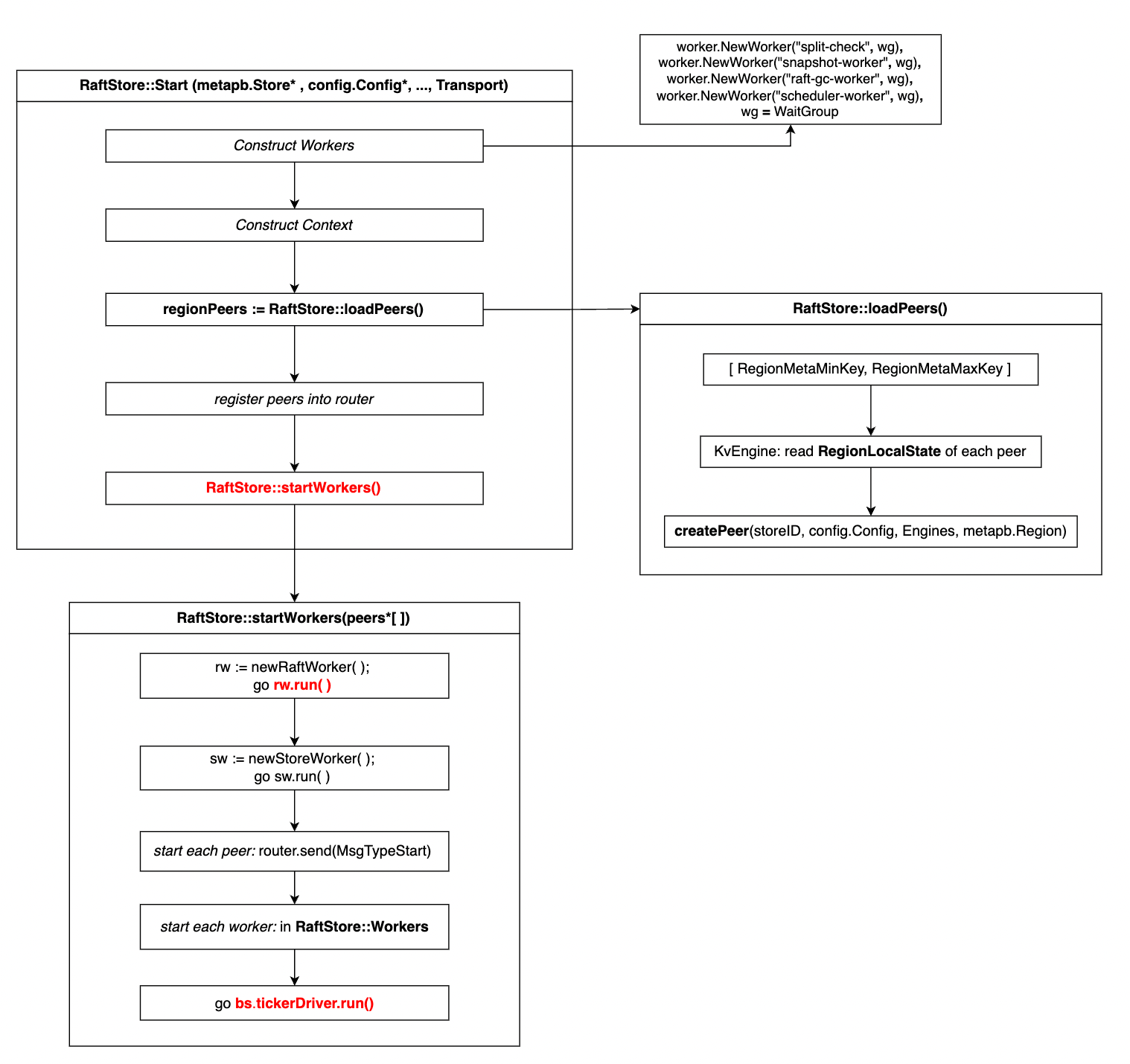
其中start函数可以看作三部分,第一部分是创建raftstore中的context和workers结构体,第二部分是读取已有的raft peers信息,第三部分是运行raftstore实例, 即startWorkers。其中我们需要重点关注loadPeers以及startWorkers函数的实现。对于前两部分,基本上就是将传入的参数写到raftstore对象对应的域中即可。
Initialization: loadPeers()
loadPeers函数会从当前节点中存储的Engine中读出之前就已经存在的raft peer的信息,然后对对应的raft peer进行创建和初始化。整个过程分为三步:
- 通过读取region_state_key来获得所有可能peer的
RegionLocalState; - 针对给定的
RegionLocalState, 创建一个peer对象; - 将创建的peer对象注册到router中,使得可以从router中找到对应的region的peer;
其中region_state_key的格式如下:
| key | Key Format | Value | DB |
|---|---|---|---|
| region_state_key | 0x01 0x03 region_id 0x01 |
RegionLocalState | Kv |
在实现时,该函数首先设定了一个key的查询范围:
startKey := meta.RegionMetaMinKey // 0x01 0x03
endKey := meta.RegionMetaMaxKey // 0x01 0x04在这两个范围之间的一定是某个region_state_key, 然后通过在KvEngine上执行一个迭代器的遍历来获得所有可能的RegionLocalState数据:
err := kvEngine.View(func(txn *badger.Txn) error {
// Create an iterator
it := txn.NewIterator(badger.DefaultIteratorOptions)
defer it.Close()
// Read all RegionStateKey
for it.Seek(startKey); it.Valid(); it.Next() {
item := it.Item()
// Check if already reaches endKey
if bytes.Compare(item.Key(), endKey) >= 0 {
break
}
// Check if this is a valid RegionStatekey format
...
...
// Read region local state by deserialization
localState := new(rspb.RegionLocalState)
err = localState.Unmarshal(val)
// Do some ser/dser check
...
peer, err := createPeer(storeID, ctx.cfg, ctx.regionTaskSender, ctx.engine, region)
regionPeers = append(regionPeers, peer)
}
return nil
})一旦读到一个合法的RegionLocalState信息,raftstore会调用createPeer来创建一个peer对象。而在创建peer对象时则经过了以下调用过程:

首先raftstore根据传入的Region信息来判断应该在当前的物理节点上创建哪个peerID的raft peer: metapb.Region*中存储了该region中每个peer的storeID以及peerID。通过遍历所有的peer信息并对比storeID就可以知道运行在当前节点上的raft peer的ID。然后调用NewPeer函数来创建一个peer对象。这个过程先创建PeerStorage作为这个raft peer的存储模块,然后创建一个RawNode结构作为raft模块的实例化。最后,判断这个region中是否只有这一个peer, 如果是的话则对这个raft peer直接发起一次campaign操作使得它成为candidate,进一步成为leader。
在完成loadPeers()调用之后,会将所有创建出的peer存储在一个array中返回,然后raftstore会将每个peer对象都注册到raftstore::router中,也就是增加peer.regionID -> peer*这个映射关系。从而使得可以通过router来访问每个peer对象。
Running Process: startWorkers()
不管是raftstore还是peer还是raft.RawNode, 这些对象终究只是静态数据的集合,要想使raft集群真正在时钟信号以及raft message等外界信息等驱动下执行还需要一个driver来持续性地更新上述静态数据的状态,这就是worker的工作。
一个raftstore对象中运行着以下负责不同职责的worker:
struct raftWorker;
struct storeWorker;
type workers struct {
raftLogGCWorker *worker.Worker
schedulerWorker *worker.Worker
splitCheckWorker *worker.Worker
regionWorker *worker.Worker
wg *sync.WaitGroup
}其中raftWorker是我们需要重点关注的内容,因为正是这个worker不断驱动着整个raft状态向前更新执行。而至于raftstore::startWorkers(*peer[])本身没有什么值得多说的,它分别创建两个特殊的worker: newRaftWorker(), newStoreWorker(), 然后启动两个coroutine分别执行这两个worker的run函数,最后对raftstore.workers中的所有Worker启动start函数。
值得说明的是,在startWorkers()函数中需要对每个peer发送MsgTypeStart信息来指示每个peer开始执行:
router.sendStore(message.Msg{Type: message.MsgTypeStoreStart, Data: ctx.store})
for i := 0; i < len(peers); i++ {
regionID := peers[i].regionId
_ = router.send(regionID, message.Msg{RegionID: regionID, Type: message.MsgTypeStart})
}最后,还需要启动tickerDriver来提供源源不断的时钟信号:
go bs.tickDriver.run()所以驱动整个raftstore的状态不断向前执行的是RaftWorker::run函数,我们将在下一节解析这一关键部分。
当StartWorkers()函数调用完成之后,整个raftstore结构就处于运行状态了,在多个持续运行的“线程“的驱动下,raftstore的状态不断被外界的输入信息和时钟信号更新,同时产生新的输出信息和状态,而RaftWorker将要负责调用每个peer的对应接口来更新状态,并对peer生成的信息和新状态进行处理,例如:将peer的输出信息发送给其他peer等。
The Driver: RaftWorker
Data structure
raftWorker包含的数据相对简单,因为它的核心在于处理每个raftpeer的状态更新和消息,而不怎么需要保存自己的状态。所以一个raftWorker只需要:
- 一个
router来确保可以将regionID引导到每个peer; - 一个channel用于存储该节点收到的外部消息;
- 一个
GlobalContext用于为worker的处理提供必要的上下文信息,例如在发送消息时需要的Transport结构体;
type raftWorker struct {
pr *router
// receiver of messages should sent to raft, including:
// * raft command from `raftStorage`
// * raft inner messages from other peers sent by network
raftCh chan message.Msg
ctx *GlobalContext
closeCh <-chan struct{}
}raftWorker::run()
之前在raftstore::startWorkers()函数中,raftstore启动一个专门的线程来执行raftWorker::run()函数来持续性地驱动raftstore的状态更新。run的实现就是一个无限循环,直到外界通过一个closeChannel给它传输一个关闭信号。在每个循环中,raftWorker会做以下工作:
- 检查
raftCh, 看是否有需要处理的消息; - 对每个
peer, 检查该peer是否有Ready状态需要更新。
整个执行流程如下所示:
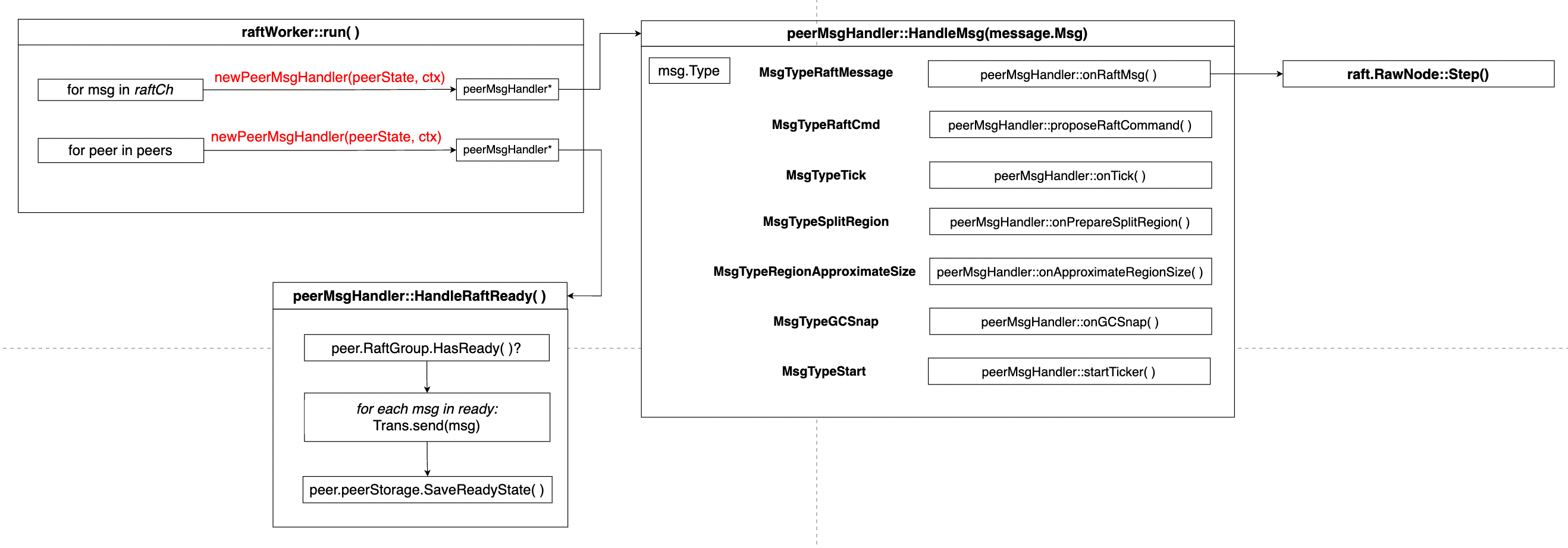
对于每个存储在raftCh中的消息,都创建一个peerMsgHandler对象并执行对应的HandleMsg消息来处理收到的消息。在调用newPeerMsgHandler之前需要利用这个message的regionID以及router中保存的regionID到peerState的映射来获得这个消息应该被传输到的peer,即构造参数中的peerState在peerMsgHandler::HandleMsg中,需要根据收到消息的类型来判断对应需要执行的函数,这里我们只关注peerMsgHandler::onRaftMsg( )调用,这个函数对收到的其他raft peer的消息进行处理,其本质上是调用peer中保存的raft.RawNode的step消息来更新状态。
另一方面,run函数会对每个peer都创建一个MsgHandler并调用HandleRaftReady()来处理每个raft rawNode生成的ready消息,包括:通过Transport发送所有RawNode生成的消息;将新的raft状态以及raft还没有persist的log进行更新;以及将raft的committed entries apply到状态机中。
Where the messages come from
Tick Message
为了对整个代码有更加细致的了解,我们同样需要考虑上面的RaftWorker在运行时收到的消息是来自什么地方,例如,tickDriver的tick消息是如何被RaftWorker检测到的;来自其他raft peer的raft message是如何从一个raft peer传输到另一个raft peer的。
首先考虑raftWorker中的raftCh的来源:
func newRaftWorker(ctx *GlobalContext, pm *router) *raftWorker {
return &raftWorker{
raftCh: pm.peerSender,
ctx: ctx,
pr: pm,
}
}可以看到这里的raftCh实际上就是router中的peerSender, 而peerSender会在router中的send被调用:
func (pr *router) send(regionID uint64, msg message.Msg) error {
msg.RegionID = regionID
p := pr.get(regionID)
if p == nil || atomic.LoadUint32(&p.closed) == 1 {
return errPeerNotFound
}
pr.peerSender <- msg
return nil
}而tickDriver的run函数中会周期性地向router中的peerSender中写入信息:
for regionID := range r.regions {
if r.router.send(regionID, message.NewPeerMsg(message.MsgTypeTick, regionID, nil)) != nil {
delete(r.regions, regionID)
}
}因此,到目前为止,我们发现了驱动整个raft系统状态前进的时钟信号来源于tickDriver, 消息传递的方式是通过向router的channel中写入消息,而这个channel正好就是raftWorker的channel.
Peer Message
根据raftworker的代码,peer message会被存储在raftCh中,而raftCh实际上就是router中的peerSender,所以向router中写入message就能实现消息的传递。raftstore中定义了一个RaftstoreRouter接口,其语义是一个raftstore的message接收方,向一个RaftstoreRouter发送消息就是对这个raftstore代表的机器发送消息。
而RaftstoreRouter定义了如下接口:
type RaftRouter interface {
Send(regionID uint64, msg Msg) error
SendRaftMessage(msg *raft_serverpb.RaftMessage) error
SendRaftCommand(req *raft_cmdpb.RaftCmdRequest, cb *Callback) error
}可以将一个RaftRouter看作是在不同raftstore之间进行通信的router,向一个RaftRouter调用SendRaftMessage或是SendRaftCommand就能向指定的raftstore发出消息。这里还定义了一个RaftstoreRouter结构,基本上就是对router的一个封装:
type RaftstoreRouter struct {
router *router
}
func (r *RaftstoreRouter) Send(regionID uint64, msg message.Msg) error {
return r.router.send(regionID, msg)
}
...此外,raftstore定义了Transport接口,用于向外界发出一条消息,消息的目的地由msg本身带有的ToPeer域来决定。其接口如下:
type Transport interface {
Send(msg *rspb.RaftMessage) error
}由于TinyKV只是一个教学使用的raftKV结构,所以整个系统并没有实现真正的网络传输模块,而是在test中实现了一个TransportMock作为网络传输的模拟,而TransportMock是对Transport接口的实现,负责将消息传递到指定的rafttstore peer上。它的实现方式是保存一个storeID到RaftRouter的map,根据给定的storeID找到该节点对应的router, 然后调用其SendRaftMessage或者SendRaftCommand接口。
整个TransportMock的结构图如下所示:
![]()
每个MockTransport保存了一个StoreID到RaftRouter的映射,每当Transport执行Send操作需要将一个消息传输到另一个raftstore上时,它从该message中读取该message的storeID,然后在映射中找到对应的RaftRouter, 调用RaftRouter::SendRaftMessage函数,将消息写到对应的raftstore上。在这个使用mock作为传输的测试中,每个RaftRouter就是另一个raftstore中的router, 所以调用SendRaftMessage就是调用router的send操作,该操作会将消息写入到router::peerSender中,也就是RaftWorker的raftCh中。这样一条消息就被传递到了另一个raftstore上。
Dealing with Client Requests
有了上面关于raftstore运行流程的基础,我们现在可以考察一个raftstore是如何处理client的请求的。由于client与raftstore,以及raft peer之间都涉及到消息传递的过程,而不同角色以及操作之间使用的消息类型和包含的数据是完全不同的,因此有必要先对这个过程中涉及到的各种消息类型进行梳理。
Transferred message type
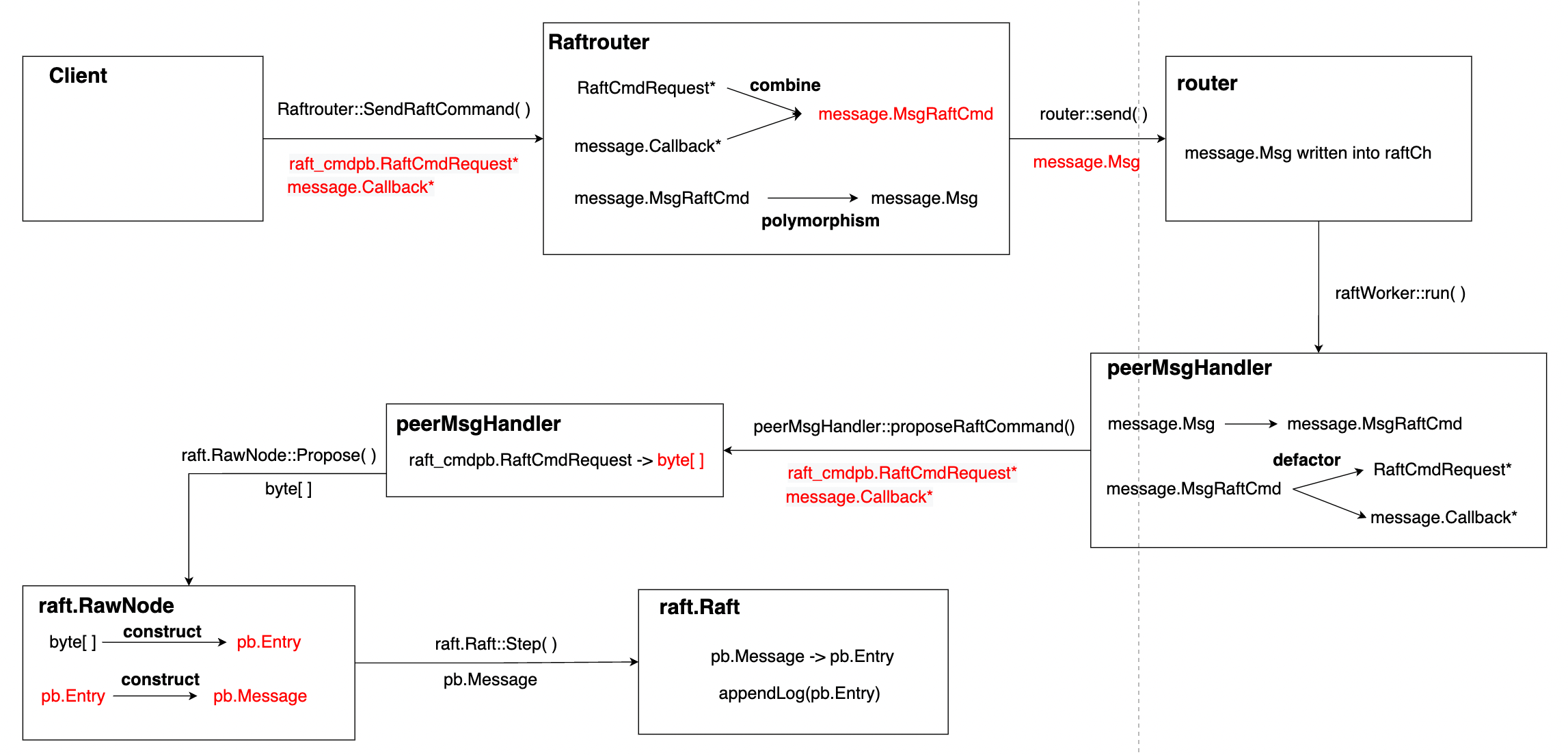
上图展示了一个来自client的request最后到达底层raft模块的过程中经过的message类型转换。其中比较重要的两个部分在于:
- 将
raft_cmdpb.RaftCmdRequest和message.Callback封装为一个整体,直到peerMsgHandler对其进行处理。 - 将
raft_cmdpb.RaftCmdRequest序列化为字节数据,并封装为一个raft的log entry。
Summary
在本文,我们考察了一个raftstore的执行流程,包括raftstore的启动初始化过程,raftworker的驱动执行流程。我们还考察了消息是如何在不同的raftstore之间传递的,尽管只是考察了单元测试中实现的一个简单的MockTransport。



