LevelDB阅读笔记-SSTable
为了保证数据的持久化, LevelDB最终会将memtable中的数据写入到底层文件中。写入的文件被称为SSTable文件,即Sorted String Table文件。这类文件包含了多个经过序列化的key-value条目,以及index block,filter block等元数据用于快速定位指定的键值对。SSTable文件需要同时支持顺序写入以及随即读写的能力。本文将介绍LevelDB中的SST文件,包括文件的格式以及文件是怎样被创建和使用的。
SSTable File Format
关于LevelDB的SSTable文件的数据布局,网上有很多介绍的文章了,这里用一幅示意图来解释:

整个SSTable文件被划分为了多个block,而不同的Block有不同的作用。主要的Block类型如下:
- Data Block: 用于存储多条经过序列化的key-value数据。
- Filter Block: 用于存储该SSTable中所有key-value数据的过滤器,可以快速判断一个key是否在该SST中
- MetaIndex Block: 存储了Filter Block的位置,是一个BlockHandlel类型,即保存了一个Block在文件中的offset以及该block的size。用于唯一地确定一个block的数据范围
- Index Block:存储了每个data block的索引,这里的索引是指一个separate key到该data block的block handle的映射。这里的separate key可以简单认为是该data block中最大的key(但不是),Index Block用于区分每个data block中存储的key的范围。
- Footer:存储了该SSTable文件的索引信息。包括到MetaIndexBlock的索引 (从而能快速找到filter block);到IndexBlock的索引。
一个SST可以分别用于读写:
- 在写操作时,SSTable由一个TableBuilder创建并顺序写入。通过向TableBuilder调用Add操作可以向该SST文件中加入key-value数据,TableBuilder在内部维护一个BlockBuilder,不断在文件末尾写入DataBlock。在TableBuilder的调用者调用Finish时,整个TableBuilder完成对Table的构造,将meta block顺序写入到文件末尾,并加上Footer表示一个SSTable文件写入完成。
- 在读操作时,TableReader会创建在一个RandomAccessFile上,从而完成对整个SST文件的随机读取。通过IndexBlock,TableReader能够定位到每个key所在的DataBlock的位置,然后在对应的DataBlock中读取key-value数据。
SSTable File的创建与写入
数据结构
SSTable的写入是由一个被称为TableBuilder的结构来管理的,涉及到的相关代码的组织如下所示:

TableBuilder将所有实际的成员放在一个Rep结构中,但是实际上也并不知道为什么要这样做,Rep这个名词在很多地方都看到过,但我也不太清楚它在编程语言中具体表示什么含义。
TableBuilder中包含了三个主要结构:
BlockBuilder data_block: 接收上层传入的key value数据,构建当前的data block.BlockBulider index_block: 为每一个data block构建一个对应的Index条目FilterBlockBuilder filter_builder: 为每个data block构建一个filter block
可以看到,TableBuilder依赖于BlockBuilder来构建具体的data block以及Index block,因此BlockBuilder是一个非常基本的数据结构。
BlockBuilder
首先需要说明,一个BlockBuilder并不会向文件里面写入实际的数据,它仅仅起到序列化的作用。当调用者通过Add(key, value)向一个Block中添加数据时,BlockBuilder仅仅只是将键值数据序列化后(包括encoding在内)添加到一个内存buffer的末尾 (std::string buffer_)。当调用者调用Finish()时,BlockBuilder会返回当前经过序列化的所有数据,由调用者来决定如何使用这些数据,即写入实际的文件等等。
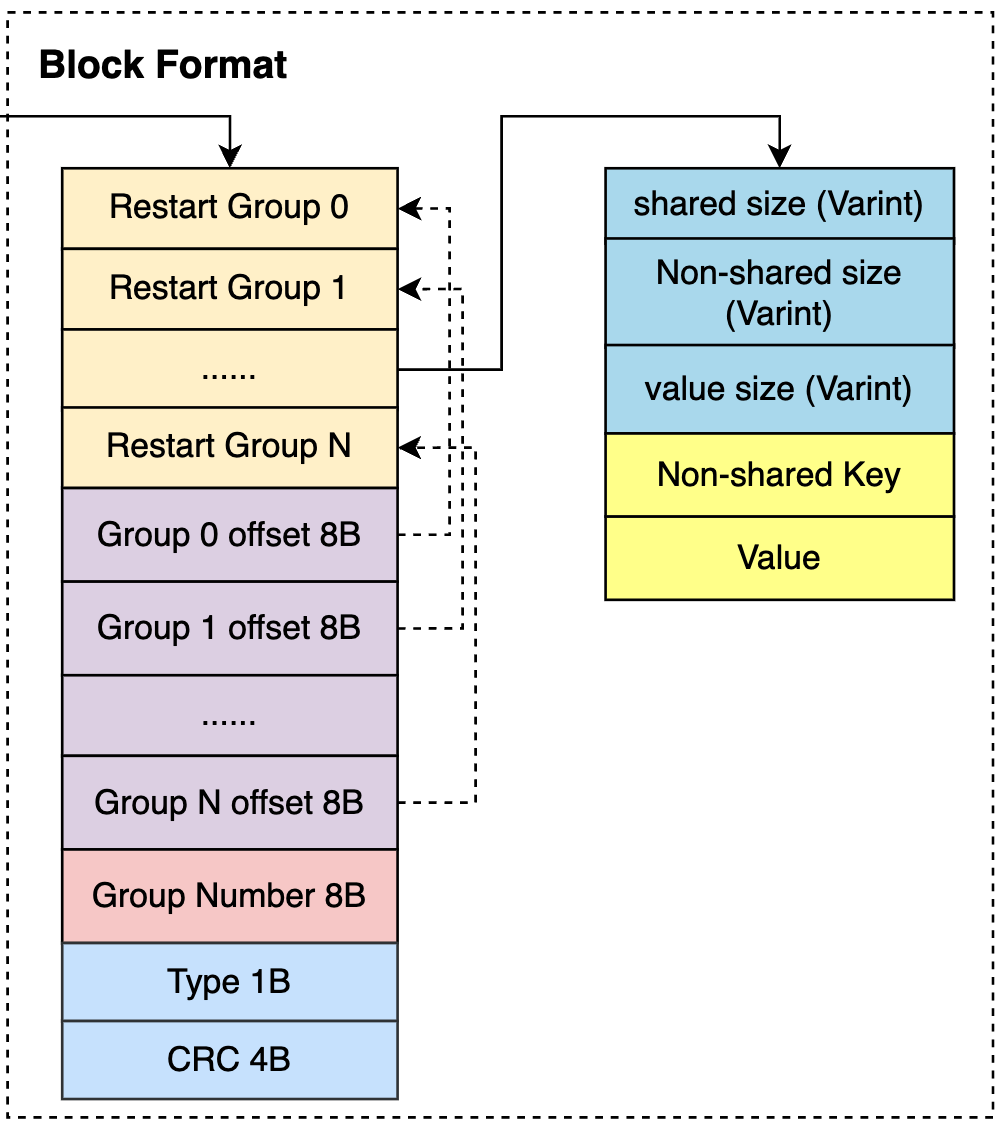
DataBlock数据排布
关于一个Block的数据排布,文章最前面的图已经有所描述了,这里重点看看DataBlock的数据排布:
Restart Group
一个DataBlock的最前端是多个Restart Group, 每个RestartGroup内部是多个key-value entry条目。采用Restart Group的原因是SSTable采用了delta encoding的方式,即存储每个key-value entry时,对于key只存储key与它的前一个key不同的部分,即non-shared key (这也是为什么BlockBuilder需要保存一个last_key_的原因)。但是这种encoding的链条不能太长,如果太长会导致读取时困难,因为需要从第一个key开始叠加解码后面的key。因此每当key的数量达到一定阈值时就开启下一个restart group。
Restart Group offset array
BlockBuilder会记录每个Restart Group的偏移。注意这个偏移是针对整个Block内部的偏移,而不是整个文件的偏移。当调用者调用BlockBuilder的Finish()时,BlockBuilder会将Restart Group offset array添加到buffer的末尾,并且写下Restart Group的数目,然后返回。
DataBlockTrailer
DataBlockTrailer是一个DataBlock最末尾的信息,包含了一个CompressionType来说明该DataBlock在做压缩时使用的压缩类型,一个4B的CRC校验码来计算整个data block的校验信息。严格来说DataBlockTrailer并不算是DataBlock的一部分,在计算一个DataBlock的BlockHandle时并没有将这5B的size计算到BlockHandle中。
调用接口
void Add(const Slice& key, const Slice& value)
该接口将一对key-value数据添加到buffer中, 首先计算当前插入key与lastkey之间的共同部分,并判断是否需要开启新的restart group。
if (counter_ < options_->block_restart_interval) {
// See how much sharing to do with previous string
const size_t min_length = std::min(last_key_piece.size(), key.size());
while ((shared < min_length) && (last_key_piece[shared] == key[shared])) {
shared++;
}
} else {
// Restart compression
restarts_.push_back(buffer_.size());
counter_ = 0;
}完成后,将当前key-value数据append到buffer中:
const size_t non_shared = key.size() - shared;
// Add "<shared><non_shared><value_size>" to buffer_
PutVarint32(&buffer_, shared);
PutVarint32(&buffer_, non_shared);
PutVarint32(&buffer_, value.size());
// Add string delta to buffer_ followed by value
buffer_.append(key.data() + shared, non_shared);
buffer_.append(value.data(), value.size());最后更新lastkey
Slice Finish()
Finish()接口将当前BlockBuilder保存的序列化数据返回,同时在整个buffer的末尾添加上restart offset array。
Slice BlockBuilder::Finish() {
// Append restart array
for (size_t i = 0; i < restarts_.size(); i++) {
PutFixed32(&buffer_, restarts_[i]);
}
PutFixed32(&buffer_, restarts_.size());
finished_ = true;
return Slice(buffer_);
}一个Block何时调用Finish()来返回数据是由BlockBuilder的上层决定的,最基本的判断方法是判断Block的大小是否超过一定阈值。在TableBuilder中使用BlockBuilder时,对于DataBlock是采用这种方法。对于IndexBlock则是只有在TableBuilder调用自己的Finish时才对对应的Index BlockBuilder调用Finish(), 这样可以保证一个SST文件中的Index Block只有一个。
void Reset()
Reset调用将整个BlockBuilder的状态重置到最初始的情况。
void BlockBuilder::Reset() {
buffer_.clear();
restarts_.clear();
restarts_.push_back(0); // First restart point is at offset 0
counter_ = 0;
finished_ = false;
last_key_.clear();
}值得说明的是,由于Finish调用需要在Block的末尾添加所有Restart Group的offset,所以必须在确定所有Add操作都完成之后才能调用Finish()。而在Add中也有一个断言:assert(finished_ == false)。如果需要将一个BlockBuilder重复使用于构建多个DataBlock,则需要在每次调用Finish()之后调用Reset()。
调用流程与执行接口
void Add(const Slice& key, const Slice& value)
整个Add操作的流程可以用下面的示意图来表示:
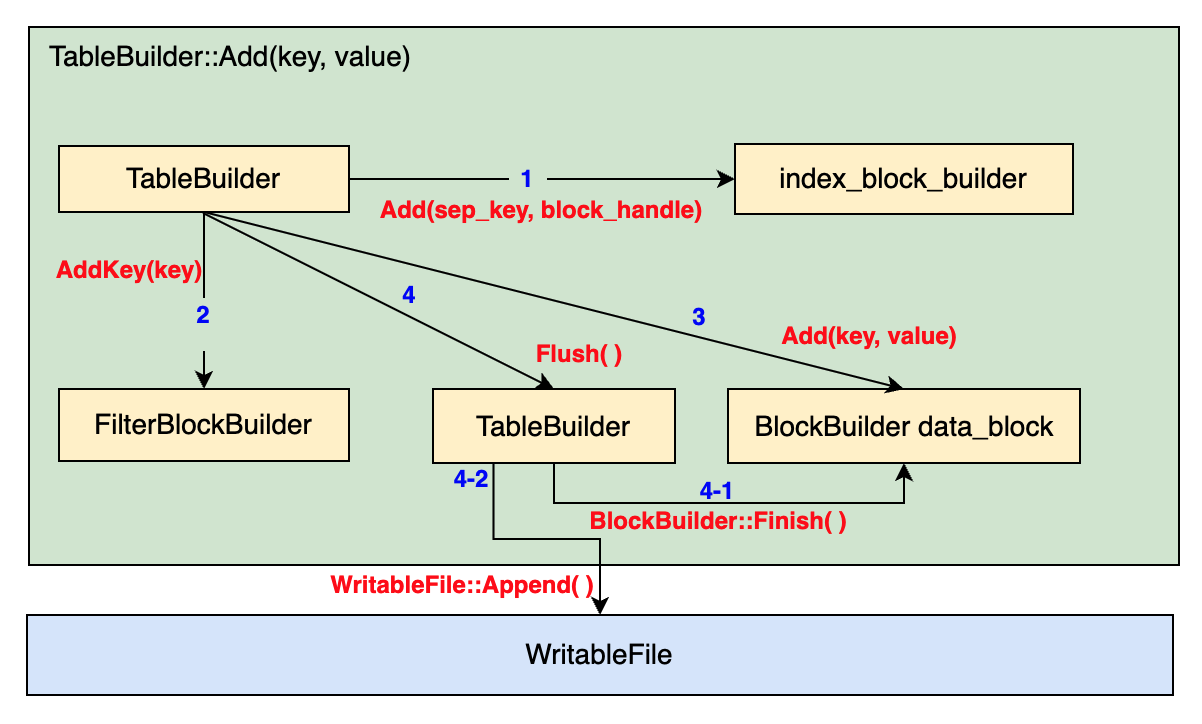
肩头上的数字1,2,3,4分别表示了该步操作的序号。箭头的末尾表示该操作调用的对象,箭头上的函数名称表示此次调用使用到的调用对象的接口。
对于TableBuilder::Add而言,该函数需要将一个key-value数据加入到整个Table中,但由于Table是由不同的Block组成的,所以实际上最后会落到对BlockBuilder的Add操作的调用。整个过程可以分为4步:
检查是否需要在Index Block中添加一个Index entry。这是因为不断向table中添加Key-value数据的过程会触发DataBlock的刷盘,一次刷盘就会诞生一个新的DataBlock,必须将上一个刷盘的DataBlock添加到IndexBlock中。这部分的代码如下所示:
void TableBuilder::Add(const Slice& key, const Slice& value) { ... if (r->pending_index_entry) { assert(r->data_block.empty()); r->options.comparator->FindShortestSeparator(&r->last_key, key); std::string handle_encoding; r->pending_handle.EncodeTo(&handle_encoding); r->index_block.Add(r->last_key, Slice(handle_encoding)); r->pending_index_entry = false; } ... }TableBuilder会为上一个DataBlock寻找一个separate key,即上面的第五行。然后将上一个DataBlock的BlockHandle编码后写入IndexBlockBuilder中。
向FilterBlock中添加该key,FilterBlock的作用是用于加速key的查询,这在之前已经说过了。
if (r->filter_block != nullptr) { r->filter_block->AddKey(key); }向DataBlock中添加key-value数据:直接调用BlockBuilder的Add接口即可
r->last_key.assign(key.data(), key.size()); r->num_entries++; r->data_block.Add(key, value);检查当前的TableBuilder是否需要将最近的一个DataBlock刷盘。判断的依据是DataBlock的大小是否已经超过设置的阈值了。将DataBlock刷盘需要调用BlockBuilder的
Finish()函数返回真实的Slice数据,然后将这部分数据调用WritableFile的Append接口直接写入const size_t estimated_block_size = r->data_block.CurrentSizeEstimate(); if (estimated_block_size >= r->options.block_size) { Flush(); }
void Flush()
Flush()操作主要包括两个调用部分,第一部分是调用自己本身的一个WriteBlock函数将DataBlock中的数据序列化之后的结果写入到WritableFile中,然后调用WritableFile的Flush接口来确保数据落盘。第二部分是创建一个新的FilterBlock。
调用
WriteBlock接口将当前的BlockBuilder中的数据append到文件中,WriteBlock内部增加了一些如数据压缩等功能:WriteBlock(&r->data_block, &r->pending_handle); if (ok()) { r->pending_index_entry = true; r->status = r->file->Flush(); }开启一个新的FilterBlock:
if (r->filter_block != nullptr) { r->filter_block->StartBlock(r->offset); }
其中关于WriteBlock的调用流程如下:TableBuilder会调用DataBlock的Finish()函数获得当前BlockBuilder的数据,该数据是一个Slice,然后对指定的Slice数据进行压缩。压缩后得到的数据会被写入到底层的WritableFile中(调用WriteRawBlock)
void TableBuilder::WriteBlock(BlockBuilder* block, BlockHandle* handle) {
// File format contains a sequence of blocks where each block has:
// block_data: uint8[n]
// type: uint8
// crc: uint32
assert(ok());
Rep* r = rep_;
Slice raw = block->Finish();
Slice block_contents;
CompressionType type = r->options.compression;
// TODO(postrelease): Support more compression options: zlib?
switch (type) {
case kNoCompression:
block_contents = raw;
break;
case kSnappyCompression: {
std::string* compressed = &r->compressed_output;
if (port::Snappy_Compress(raw.data(), raw.size(), compressed) &&
compressed->size() < raw.size() - (raw.size() / 8u)) {
block_contents = *compressed;
} else {
// Snappy not supported, or compressed less than 12.5%, so just
// store uncompressed form
block_contents = raw;
type = kNoCompression;
}
break;
}
}
WriteRawBlock(block_contents, type, handle);
r->compressed_output.clear();
block->Reset();
}WriteRawBlock在将数据追加到底层的文件的同时,也会对写入的block_contents生成CRC校验码,同时增加compression的type。形成一个5B的BlockTrailer,这个Trailer会被追加到该DataBlock的末尾。
Status Finish()
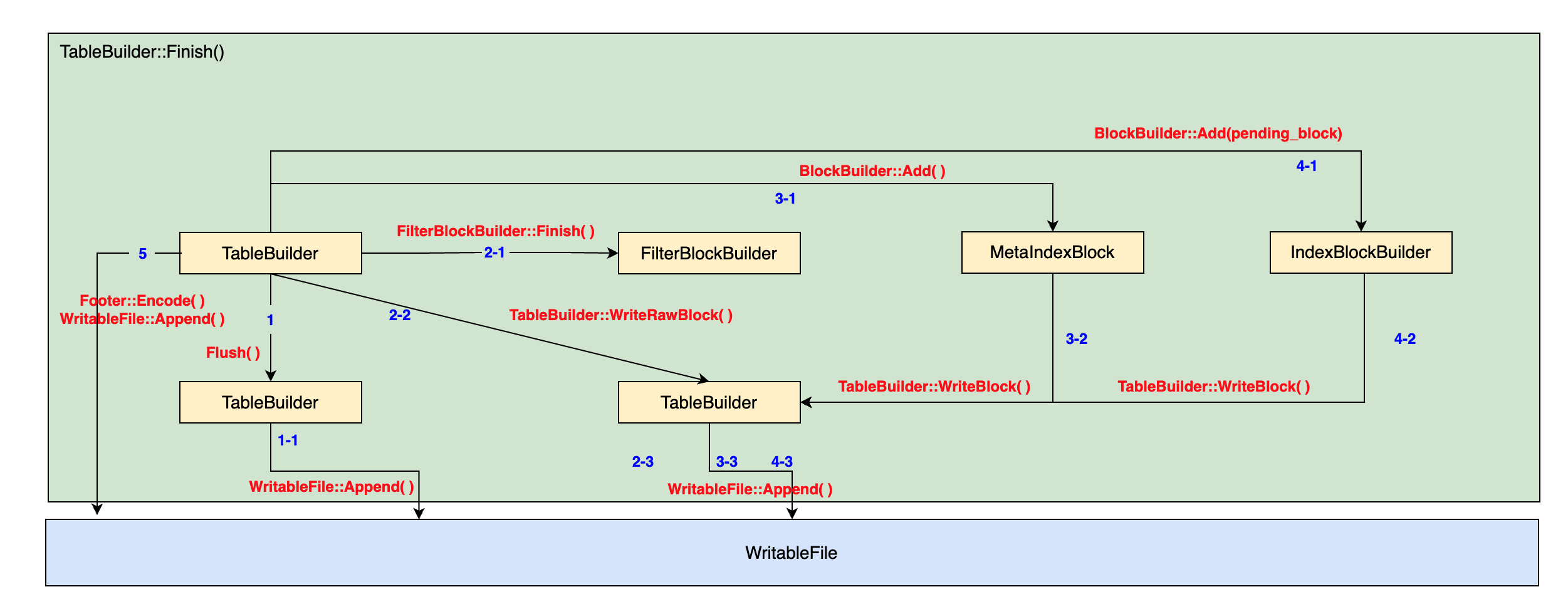
TableBuilder::Finish()的调用会结束对当前的Table的构建,也就是将最后留下的DataBlock Flush到文件中,然后将后续的多个MetaBlock追加到文件末尾。最后添加Footer作为整个文件的元数据。整个函数的执行过程也可以分为以下5个部分:
刷新现有的DataBlock:
Status TableBuilder::Finish() { Rep* r = rep_; Flush(); assert(!r->closed); r->closed = true; ... }将FilterBlock的数据添加到文件中
// Write filter block if (ok() && r->filter_block != nullptr) { WriteRawBlock(r->filter_block->Finish(), kNoCompression, &filter_block_handle); }构建MetaIndexBlock的数据,简单而言MetaIndexBlock保存的是FilterBlock的BlockHandle,但是由于MetaIndexBlock采用的是BlockBuilder,其Add接口需要一对key value数据。所以这里需要手工共建一个key,LevelDB选择了一个人工可读的key名称:
if (ok()) { BlockBuilder meta_index_block(&r->options); if (r->filter_block != nullptr) { // Add mapping from "filter.Name" to location of filter data std::string key = "filter."; key.append(r->options.filter_policy->Name()); std::string handle_encoding; filter_block_handle.EncodeTo(&handle_encoding); meta_index_block.Add(key, handle_encoding); } // TODO(postrelease): Add stats and other meta blocks WriteBlock(&meta_index_block, &metaindex_block_handle); }为刚刚刷新的最后一个DataBlock在IndexBlock中构建一个索引的entry, 然后将所有的IndexBlock的数据追加到文件中。
if (ok()) { if (r->pending_index_entry) { r->options.comparator->FindShortSuccessor(&r->last_key); std::string handle_encoding; r->pending_handle.EncodeTo(&handle_encoding); r->index_block.Add(r->last_key, Slice(handle_encoding)); r->pending_index_entry = false; } WriteBlock(&r->index_block, &index_block_handle); }为整个文件添加一个Footer, 并将其追加到整个文件末尾。
if (ok()) { Footer footer; footer.set_metaindex_handle(metaindex_block_handle); footer.set_index_handle(index_block_handle); std::string footer_encoding; footer.EncodeTo(&footer_encoding); r->status = r->file->Append(footer_encoding); if (r->status.ok()) { r->offset += footer_encoding.size(); } }
SSTable File的读取与遍历
LevelDB的SSTable数据读取涉及到的相关结构和类如下所示:

Table: 按照代码注释中的说法,一个Table就是一个不可变的Map,提供了从Key到Value的映射。在LevelDB中,Table并没有直接提供类似于Table::Get(key, value)这样的接口,而是提供了一个迭代器的创建接口,通过调用迭代器的Seek()接口来找到目标key。Block: Block是对一个DataBlock的读取接口,类似于在写入SST时的BlockBuilder,这里的Block对从文件中读上来的“裸数据”进行解析,实现Get的功能。类似于Table,Block也不直接提供Get的接口,而是提供了在一个Block上创建迭代器的接口。FilterBlockReader: 提供了KeyMayMatch接口,用于在FilterBlock中查询一个指定的key是否存在。
对于Table而言,比较重要的接口包括:
- 对一个已有的immutable的file创建一个Table,即:
Table::Open(const Options, RandomAccessFile*, uint64_t, Table**)接口。 - 在创建出来的Table中进行key-value数据的查询,即:
Table::NewIterator接口。
Table的创建
Table::Open
从一个已有的RandomAccessFile创建一个Table的过程需要下面几个步骤:
从该RandomAccessFile中读取整个SST的Footer并解析:
Status Table::Open(const Options& options, RandomAccessFile* file, uint64_t size, Table** table) { char footer_space[Footer::kEncodedLength]; Slice footer_input; Status s = file->Read(size - Footer::kEncodedLength, Footer::kEncodedLength, &footer_input, footer_space); if (!s.ok()) return s; Footer footer; s = footer.DecodeFrom(&footer_input); ... }从解析的Footer中读出IndexBlock的位置,然后将IndexBlock的数据读入到内存中。这是因为对一个SST进行kv查询时需要依赖IndexBlock的数据来定位目标key所在的位置,这是一个不可避免的操作,将IndexBlock的数据cache在内存中可以加速读操作。
Status Table::Open(const Options& options, RandomAccessFile* file, uint64_t size, Table** table) { ... BlockContents index_block_contents; ReadOptions opt; if (options.paranoid_checks) { opt.verify_checksums = true; } s = ReadBlock(file, opt, footer.index_handle(), &index_block_contents); ... }其中BlockContents用于保存从file中读取到的“裸数据”,并且增加了一些所有权的管理(例如,如果多个线程都需要读取同一个Block的数据,由于SST的数据不可变,所以只需要分配一份Block的内存即可,因此这涉及到内存释放的问题)
ReadBlock是一个从给定的RandomAccessFile中读取指定Block的接口,并且内部提供了CRC校验等功能。构建一个Table结构,将数据域进行填充,并且执行
ReadMeta函数来将FilterBlock的数据读出:Status Table::Open(const Options& options, RandomAccessFile* file, uint64_t size, Table** table) { ... if (s.ok()) { // We've successfully read the footer and the index block: we're // ready to serve requests. Block* index_block = new Block(index_block_contents); Rep* rep = new Table::Rep; rep->options = options; rep->file = file; rep->metaindex_handle = footer.metaindex_handle(); rep->index_block = index_block; rep->cache_id = (options.block_cache ? options.block_cache->NewId() : 0); // (kqh) Filter data will be constructed in ReadMeta rep->filter_data = nullptr; rep->filter = nullptr; *table = new Table(rep); (*table)->ReadMeta(footer); } ... }其中ReadMeta函数会根据Footer找到
MetaIndexBlock所对应的BlockHandle,然后从文件中读取这部分数据,以FilterPolicy的名字作为key来找到对应的FilterBlock对应的BlockHandle,然后File中读出真正的FilterBlock数据(创建一个FilterReader)。
ReadBlock
ReadBlock是一个通用的从ReadomAccessFile中读取指定块的接口。并且会根据对应Block的Trailer进行CRC校验来保证读取数据的正确性,以及对数据进行解压缩操作。整个函数的实现也非常直接:
首先是直接调用RandomAccessFile的Read接口来读到指定Block大小的数据:
Status ReadBlock(RandomAccessFile* file, const ReadOptions& options, const BlockHandle& handle, BlockContents* result) { result->data = Slice(); result->cachable = false; result->heap_allocated = false; // Read the block contents as well as the type/crc footer. // See table_builder.cc for the code that built this structure. size_t n = static_cast<size_t>(handle.size()); char* buf = new char[n + kBlockTrailerSize]; Slice contents; Status s = file->Read(handle.offset(), n + kBlockTrailerSize, &contents, buf); if (!s.ok()) { delete[] buf; return s; } // (kqh) Expect to read n + kBlockTrailerSize, but not get that many data if (contents.size() != n + kBlockTrailerSize) { delete[] buf; return Status::Corruption("truncated block read"); } ... }然后进行CRC码校验:
Status ReadBlock(RandomAccessFile* file, const ReadOptions& options, const BlockHandle& handle, BlockContents* result) { ... const char* data = contents.data(); // Pointer to where Read put the data if (options.verify_checksums) { const uint32_t crc = crc32c::Unmask(DecodeFixed32(data + n + 1)); const uint32_t actual = crc32c::Value(data, n + 1); if (actual != crc) { delete[] buf; s = Status::Corruption("block checksum mismatch"); return s; } } ... }最后检查该Block的压缩类型,如果是Snappy压缩则需要额外分配空间来写入解压缩之后的数据,我们省略这部分代码, 具体的内容感兴趣地话可以参考代码实现。
ReadMeta
ReadMeta首先根据Footer的信息读出MetaIndexBlock的数据,该block中保存了一个filter policy到其对应的FilterBlock的BlockHandle数据。
Status Table::ReadMeta(const Footer& footer) {
...
BlockContents contents;
if (!ReadBlock(rep_->file, opt, footer.metaindex_handle(), &contents).ok()) {
// Do not propagate errors since meta info is not needed for operation
return;
}
Block* meta = new Block(contents);
...
}在MetaIndexBlock中搜索一个filter policy指定的BlockHandle时,通过显式指定其名字来找到对应的FilterBlock的BlockHandle,然后读取对应的Block中的数据:
Status Table::ReadMeta(const Footer& footer) {
...
Iterator* iter = meta->NewIterator(BytewiseComparator());
std::string key = "filter.";
key.append(rep_->options.filter_policy->Name());
iter->Seek(key);
if (iter->Valid() && iter->key() == Slice(key)) {
ReadFilter(iter->value());
}
...
}而ReadFilter函数则是对读取出来的裸数据,即ReadBlock获得的数据构建一个FilterBlock。
Table创建迭代器进行遍历和Seek操作
Table通过创建一个迭代器来提供对整个Table的遍历以及Seek到指定key位置的功能。LevelDB中迭代器的基类是Iterator,所有其他具体的迭代器都是对这个抽象基类的实现。在Table这一个模块中,我们涉及到两种具体的迭代器, 如下所示:

TwoLevelIterator: 即整个Table返回的迭代器,提供在整个Table的Key-Value数据上进行迭代的接口。称其为TwoLevel是因为这个迭代器同时保存了对IndexBlock的迭代器以及对某个DataBlock的迭代器(保存为IteratorWrapper)。并且在进行遍历或者seek操作时需要先对IndexBlock的迭代器进行seek,然后再对目标Block的迭代器进行Seek。Block::Iter: 在某个Block上进行迭代的迭代器。提供对整个Block内数据进行迭代的功能。IteratorWrapper: 基本上只是对具体的Iterator的一层封装,按照代码注释的说法,这样封装具有更好的cache局部性(为啥)?
当Table需要创建一个针对该Table的Iterator时,它直接调用NewTwoLevelIterator, 但是Table会先在index block上创建一个Block::Iter类型,再将其作为参数传递给NewTwoLevelIterator。
由于DataBlock和IndexBlock实际上都是采用Block格式来保存key到value的映射,因此二者创建的Iterator类型是相同的,都是Block::Iter。 我们先介绍Block::Iter的实现。
Block::Iter的实现
数据成员

BlockIter的各个域到其数据排布的映射如上图所示。其中:
restarts_, nm_restarts_限定了整个SST的restart group index array的位置。current_限定了当前的读指针的位置,在正常情况下,它只能在数据区移动,即多个Restart group之间。restart_index_说明了当前的current_指针所在的Restart Group的位置。
接下来我们解析Block::Iter的几个操作接口, Iterator基类约定了需要实现多个接口函数,但为了简单考虑这里我们只看几个比较重要的函数实现:
Next(), 将当前的key value移动到下一个位置,需要更新current指针,``restart_index``等多个成员变量。Seek(), 将迭代器移动到指定的key的位置。Valid(), 检查当前迭代器是否有效。
Next()的实现
Next()的实现只是简单地调用了一个ParseNextKey的函数,在这个函数内部,迭代器将解析一个Restart Group内部的key-value数据:首先,该函数读取一个key-value pair的header, 即一个triple: shared size, non-shared size, value size。
bool Block::Iter::Next() {
// Move the current read pointer to the position of next key-value pair, preparing for reading
// its header triple
current_ = NextEntryOffset();
const char* p = data_ + current_;
const char* limit = data_ + restarts_; // Restarts come right after data
if (p >= limit) {
// No more entries to return. Mark as invalid.
current_ = restarts_;
restart_index_ = num_restarts_;
return false;
}
// Decode next entry
uint32_t shared, non_shared, value_length;
p = DecodeEntry(p, limit, &shared, &non_shared, &value_length);
...
}
// Calculate the offset of the next key-value pair, based on current value pointer and value size
inline uint32_t NextEntryOffset() const {
return (value_.data() + value_.size()) - data_;
}通过调用DecodeEntry, 拿到下一个键值对的header消息,同时返回的指针p指定了non-shared key的位置。第二步就是通过拼接shared-key部分的数据与non-shared key部分的数据来得到完整的key。
bool Block::Iter::Next() {
...
key_.resize(shared);
key_.append(p, non_shared);
value_ = Slice(p + non_shared, value_length);
while (restart_index_ + 1 < num_restarts_ &&
GetRestartPoint(restart_index_ + 1) < current_) {
++restart_index_;
}
return true;
}这里值得注意的是需要更新一下restartindex。
Seek()的实现
在一个DataBlock内部找到一个指定的key(或者与该key相近的位置)的方法是在整个DataBlock内部进行二分查找。整个二分查找的粒度是按照restart group来的,也就是说,先确定目标key所在的restart group,然后在这个restart group内部顺序遍历找到目标key或者目标key的下一个位置。
而通过二分查找确定目标key所在的restart group时,使用该restart group的第一个key来与目标key进行比较,如果目标key比该key大,说明该目标key在这个restart group或其之后的restart group中;否则说明目标key在该key之前的restart group
void Block::Iter::Seek(const Slice& target) {
...
// You may treat left and right are initialized to be 0 and num_restarts_ - 1
// respectively
while (left < right) {
uint32_t mid = (left + right + 1) / 2;
uint32_t region_offset = GetRestartPoint(mid);
uint32_t shared, non_shared, value_length;
const char* key_ptr =
DecodeEntry(data_ + region_offset, data_ + restarts_, &shared,
&non_shared, &value_length);
if (key_ptr == nullptr || (shared != 0)) {
CorruptionError();
return;
}
Slice mid_key(key_ptr, non_shared);
if (Compare(mid_key, target) < 0) {
// Key at "mid" is smaller than "target". Therefore all
// blocks before "mid" are uninteresting.
left = mid;
} else {
// Key at "mid" is >= "target". Therefore all blocks at or
// after "mid" are uninteresting.
right = mid - 1;
}
}
...
}一旦目标key所在的restart group或者相邻的group被定位到了之后,就可以顺序地在该restart group内部查找指定的key:
void Block::Iter::Seek(const Slice& target) {
...
while (true) {
if (!ParseNextKey()) {
return;
}
if (Compare(key_, target) >= 0) {
return;
}
}
...
}值得注意的是,上面通过二分查找找到的restart group并不一定就是目标key所在的restart group;但一定保证当前的key一定满足 key < target_key。
Valid()的实现
valid()简单地检查当前的读指针是否在一个有效的范围内即可, 即不要超出restart offset array所在的数据范围即可。
bool Valid() const override { return current_ < restarts_; }在Next调用的时候,函数会检查当前的读指针范围是否已经抵达了整个DataBlock的restart offset array部分,如果是,则将整个迭代器的状态置为无效。另外,一些数据不一致之类的错误也会将迭代器状态置为无效,例如发现数据编码出现了问题:
bool Block::Iter::Next() {
...
uint32_t shared, non_shared, value_length;
p = DecodeEntry(p, limit, &shared, &non_shared, &value_length);
if (p == nullptr || key_.size() < shared) {
CorruptionError();
return false;
}
...
}
void Block::Iter::CorruptionError() {
current_ = restarts_;
restart_index_ = num_restarts_;
status_ = Status::Corruption("bad entry in block");
key_.clear();
value_.clear();
}TwoLevelIterator的实现
TwoLevelIterator的数据域到对应的SST数据布局的关系如下所示:
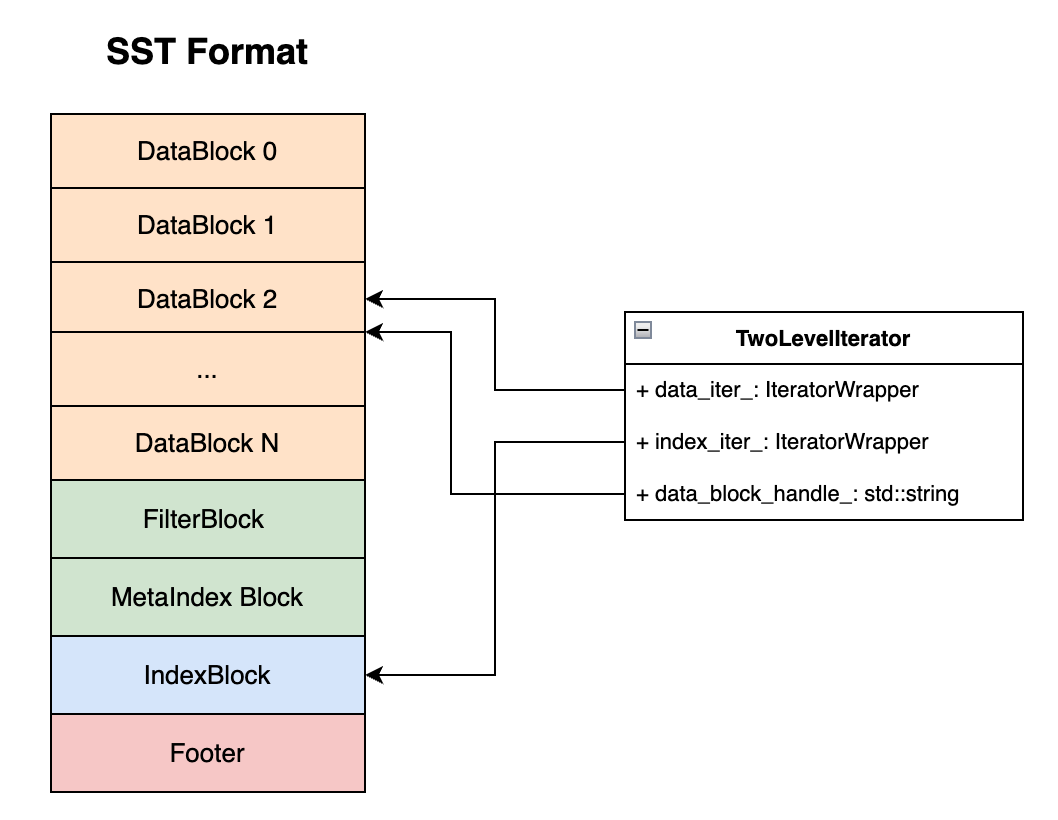
其中TwoLevelIterator保存了两个Iterator,分别用于在IndexBlock中找对应Block, 以及在对应的DataBlock中找到对应的key。
Next()的实现
TwoLevelIterator的Next首先对现有的DataBlock的迭代器调用Next(), 然后检查该data block的迭代器是否已经到达了整个DataBlock的末尾了,如果到达了,则对Index Iterator读取下一个data block的位置,然后构建一个新的对data block的迭代器。
如果当前的data block已经到达了最后一个位置,那么会对indexiter调用next函数,获得下一个data block的位置,然后调用InitDataBlock来获得对下一个DataBlock的迭代器。
void TwoLevelIterator::Next() {
assert(Valid());
data_iter_.Next();
SkipEmptyDataBlocksForward();
}
void TwoLevelIterator::SkipEmptyDataBlocksForward() {
while (data_iter_.iter() == nullptr || !data_iter_.Valid()) {
// Move to next block
if (!index_iter_.Valid()) {
SetDataIterator(nullptr);
return;
}
index_iter_.Next();
InitDataBlock();
if (data_iter_.iter() != nullptr) data_iter_.SeekToFirst();
}
}总结
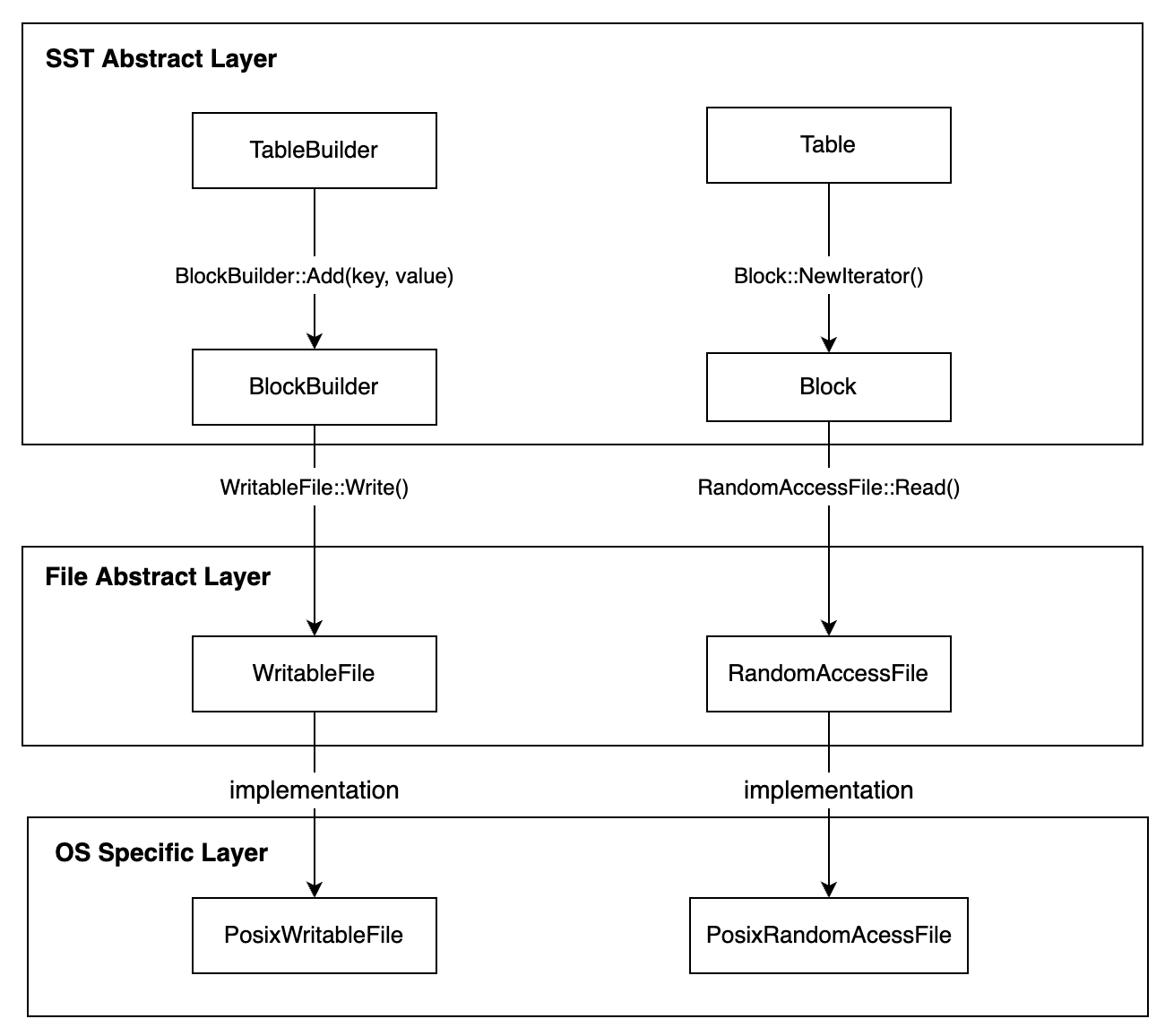
到目前为止,我们已经解析了LevelDB中底层的文件实现:LevelBD使用 WritableFile, RandomAccessFile等作为抽象基类来提供一层对文件的使用抽象;根据不同的操作系统提供系统相关的具体文件实现,例如Posix系统使用file descriptor以及write, read等系统调用来实现。
基于WritableFile, RandomAccessFile等抽象的文件概念,LevelDB构建了SST这一抽象概念,一个SST代表了一个持久化的键值映射。上层可以通过TableBuilder来插入一个键值对,也可以通过TableReader来创建迭代器来对数据进行遍历和点查。整个LevelDB对于文件与SST管理的层级如下图所示: