
TinyKV Course: RaftStore源码解析
TinyKV RaftStore源码解析
TinyKV Course的Lab2B要求我们基于Raft Module实现一个key-value存储服务,在涉及到的模块中最重要的就是raftstore。 因此我们先对其相关的代码进行阅读,本文是代码阅读的总结,可能会随着后面阅读的深入继续更新。
Overview
raftstore是TinyKV中Raft存储的核心部分,它将raft::RawNode, storage, Transport等部分拼接在了一起。并且由于TiKV采用的是Multi-Raft, 一台服务机器上可能会运行多个raft peer, 这些不同region的raft peer都被同一个raftstore所管理。

上图展示了raftstore大概的结构,这里并没有展示一个raftstore结构体中的所有数据成员,而是选择了一些较为关键的部分。包括如下部分:
router: 由于一个raftstore中可能运行着多个raft peer,所以raftstore需要对收到的message按照region id进行分发,每个raft peer独立地处理自己这个raft region中的数据。router结构就起到这个分发的作用。GlobalContext:保存了raftstore运行时的一些上下文信息,这里展示了两个最重要的部分:Transport用于发送raft message给其他raftstore,Engines包含了两个持久化的key-value数据库,一个用于持久化raft log,一个作为raft的状态机。因为raftstore里面有多个来自不同region的raft peer,所以需要在RaftDB中进行区分,区分的方式是使用region_id作为key的prefix。Ticker: 周期性地发送时钟tick信息,用于驱动raft peer的状态向前更新。RaftWorker: 一个周期性运行的worker,它会在一个for loop中做以下工作:查询是否有其他raft server发来的消息,如果有则对其进行处理:NewMsgHandler(); 对每个raft peer进行状态更新,持久化log entry,apply entry到state machine等。Workers: 一些其他相关的Worker, 例如raft需要定期做log compaction等动作。
Source Code Overview
在正式开始解析代码之前,我们需要先对每个模块包含了哪些类,以及每个类包含了哪些成员数据进行调查。经过阅读,相关的类以及各自的成员如下:

在上面的UML图中,我们将raftstore划分为了四个模块:
Ticker Module: 作为整个raftstore的ticker模块,不断发出tick信号来驱动整个raftstore进行对应的状态更新等操作。raft module: 作为整个raftstore最核心的部分,raft module的核心数据结构是peer, 一个peer是对raft.RawNode的进一步封装。包含了存储模块,snapshot模块等内容。RaftWorker根据tick信号来不断更新raft模块中每个raft peer的状态。storage module: 包含了PeerStorage, 这是一个对raft.Storage接口的实现,用于读取和持久化raft相关的持久化数据。其底层实现采用了一个持久化键值数据库badger.DBGloablContext: 包含了各个模块在运行时需要的一些上下文信息,例如raft peer在发送消息时需要Transport来发送。
综上所述,raftstore就是将上述各个模块链接在一起的adapter, 它将各个部分初始化,例如从底层的存储系统中读取之前已经存在的raft peer状态,初始化状态机等;然后创建一个RaftWorker持续在TickDriver的驱动下对各个部分进行更新操作。
Ticker Module
Data structure
我们首先对Ticker Module进行梳理,因为这部分代码相对比较简单,和其他模块的耦合也比较松。可以单独拿出来作为一个独立的模块。Ticker在整个Raft模块中的作用就是每过一段时间就发出一个时钟信号,由这个时钟信号来驱动Raft,snapshot,Log GC等模块的工作向前运作。
TickerModule模块的内容如下:
type tickDriver struct {
baseTickInterval time.Duration
newRegionCh chan uint64
regions map[uint64]struct{}
router *router
storeTicker *ticker
}
type ticker struct {
regionID uint64
tick int64
schedules []tickSchedule
}
type tickSchedule struct {
runAt int64
interval int64
}每个域的作用如下:
baseTickInterval说明了这个TickDriver每过多少时间需要发出一个Tick信号。newRegionCh用于接收是否有一个newRegion的请求。regions保存了在这个server上运行的所有raft peer的RegionID。router提供了send接口,tickDriver可以使用该接口向一个指定的region的peer发出tick消息;storeTicker保存了和store相关的元数据,在raftstore中,除了Raft模块本身需要周期性地获取tick消息向前更新状态,一些store活动也需要向前执行, 例如Snapshot, LogGC等。这些活动也都是周期性进行的,所以需要一个tick。storeTicker保存了这些活动的tick元数据,包括:每多少个tick触发一次;现在已经执行了多少个tick了。
对于ticker, 它包含了一个tickSchedule数组,该数组使用一个int类型来索引,其值实际上枚举了几种store活动的情况:
const (
PeerTickRaft PeerTick = 0
PeerTickRaftLogGC PeerTick = 1
PeerTickSplitRegionCheck PeerTick = 2
PeerTickSchedulerHeartbeat PeerTick = 3
)
const (
StoreTickSchedulerStoreHeartbeat StoreTick = 1
StoreTickSnapGC StoreTick = 2
)每个tickSchedule包含了一个interval和一个runAt元素,interval用于表示该活动应该每多少个tick执行一次;runAt表示该活动下一轮应该在哪个tick时运行。当一个store动作被执行之后,可以通过runAt = tick + interval来更新该store动作的下一次运行时间。这实际上就是ticker.Schedule()的执行流程。
Ticker Running
TickDriver通过run函数来启动一个ticker, 这个ticker将会在一个死循环中运行下去,每过一段时间发出一个tick信号给router中的raft peer,然后检查是否有对应的store活动可以可以执行:
func (r *tickDriver) run() {
timer := time.Tick(r.baseTickInterval)
for {
select {
case <-timer:
for regionID := range r.regions {
if r.router.send(regionID, message.NewPeerMsg(message.MsgTypeTick, regionID, nil)) != nil {
delete(r.regions, regionID)
}
}
r.tickStore()
case regionID, ok := <-r.newRegionCh:
if !ok {
return
}
r.regions[regionID] = struct{}{}
}
}
}run函数创建一个timer, 这个timer是一个channel,另一端会每过一段时间就发出一个一个time结构体。在run函数中,使用一个死循环来不断接收来自这个timer的消息。而每经过baseTickInterval的时间,tickDriver就会给router中保存的每个peer发出一个MsgTypeTick消息,使得Raft能知道已经经过了一个tick了,而RaftWorker也会在一个死循环中检查当前是否有tick消息,然后调用raft.RawNode的step来使得raft的状态得到更新。
每经过一个tick,TickDriver会在storeTicker中调用tickStore来检查是否有可执行的store活动, 即tickStore函数:
func (r *tickDriver) tickStore() {
r.storeTicker.tickClock()
for i := range r.storeTicker.schedules {
if r.storeTicker.isOnStoreTick(StoreTick(i)) {
r.router.sendStore(message.NewMsg(message.MsgTypeStoreTick, StoreTick(i)))
}
}
}isOnStoreTick就是检查之前提到的tickSchedule中每个store动作的runAt是否达到,如果达到,则通过sendStore发起一个store动作调用。
Storage Module
接下来我们介绍storage module, storage module主要实现了一个类PeerStorage, 作为raft模块的底层持久化存储部分,该类实现了raft.Storage这一接口。
PeerStorage data structure
type PeerStorage struct {
// current region information of the peer
region *metapb.Region
// current raft state of the peer
raftState *rspb.RaftLocalState
// current apply state of the peer
applyState *rspb.RaftApplyState
// current snapshot state
snapState snap.SnapState
// regionSched used to schedule task to region worker
regionSched chan<- worker.Task
// generate snapshot tried count
snapTriedCnt int
// Engine include two badger instance: Raft and Kv
Engines *engine_util.Engines
// Tag used for logging
Tag string
}metapb.Region包含了该raft peer的region信息,包括该region的Id,每个peer的id和storeId等(StoreID说明了peer在哪台机器上)。这是因为一台机器上可能有多个raft peer, 它们都一起存储在一个kv中,所以需要在存储的时候加上regionId作为前缀。rspb.RaftLocalState和raspy.RaftApplyState存储了一个raft peer的状态,如下所示:type RaftLocalState struct { HardState *eraftpb.HardState LastIndex uint64 LastTerm uint64 } type HardState struct { Term uint64 Vote uint64 Commit uint64 } type RaftApplyState struct { // Record the applied index of the state machine to make sure // not apply any index twice after restart. AppliedIndex uint64 // Record the index and term of the last raft log that have been truncated. (Used in 2C) TruncatedState *RaftTruncatedState } type RaftTruncatedState struct { Index uint64 Term uint64 }其中
RaftLocalState.LastIndex和RaftLocalState.LastTerm记录了该storage中最后一个log entry的index和term。HardState记录了Raft论文中提到的必须要持久化的部分,包括一个raft peer当前的term,votefor。raft的CommitIndex并不要求持久化,但是在state machine被持久化的情况下commitIndex和applyIndex都需要被持久化来避免重复的apply和commit。RaftTruncatedState是关于一个raft peer在做snapshot时的状态,它记录了最后一个被截断的log entry的index和term。snap.SnapState是关于snapshot的,这部分暂时省略。engine_util.Engines封装了两个key-value store,一个用于保证raft状态的持久化,一个用于作为raft状态机。
Persistence Procedure
由于这里的engine需要存储来自不同region的raft peer的状态,所以需要在存储时对key增加额外的内容来区分这些状态是来自不同的raft peer,这些内容在存储时的格式如下:
| Key | Key Format | Value | DB |
|---|---|---|---|
| raft_log_key | 0x01 0x02 region_id 0x01 log_idx |
Entry | Raft |
| raft_state_key | 0X01 0X02 region_id 0x02 |
RaftLocalState | Raft |
| apply_state_key | 0x01 0x02 region_id 0x03 |
RaftApplyState | kv |
| region_state_key | 0x01 0x03 region_id 0x01 |
RegionLocalState | Kv |
下面分析PeerStorage相关的代码,主要包含两个方面:1. PeerStorage的创建与初始化;2. PeerStorage对raft状态(包括log)的持久化过程。
Object Creation & initialization
为了创建一个PeerStorage结构,需要从Engine中尝试读出之前已经存在的raft_local_state和apply_state。整个初始化的过程如下:
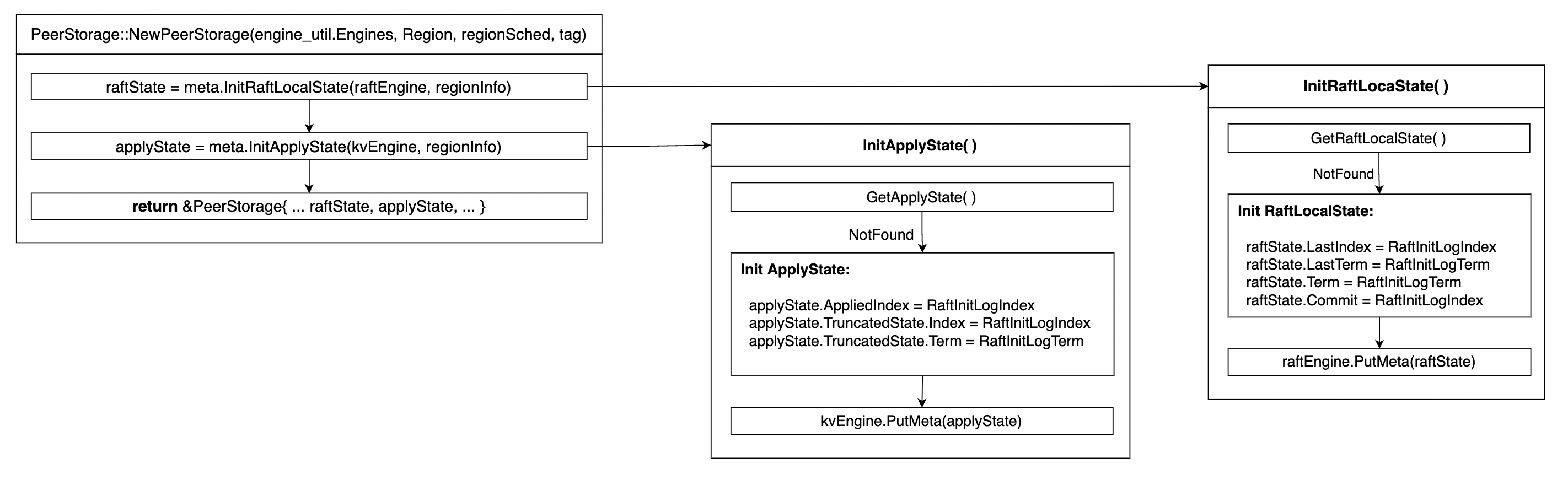
NewPeerStorage会从engine中分别读取RaftLocalState和RaftApplyState,并将它们作为PeerStorage构造函数的一部分存储在PeerStorage对象中。因此,当raft模块调用PeerStorage的InitState函数时,它只是简单地将局部存储的raftLocalState和ConfState返回给上层。
initRaftLocalState会构造一个初始化的RaftLocalState, 这包含两个方面:1. 直接从raftDB中以raft_state_key作为key读取对应的value数据; 2. 如果raftDB中没有这样一个key, 则说明这个raft peer是第一次启动,需要做初始化。初始化时需要对raft的状态进行设置,这里设置raft的term为RaftInitLogTerm, 即为5,设置raft的log的lastIndex为RaftInitLogIndex, 其值也为5。然后将初始化得到的状态调用PutMeta进行初始化。initApplyState()做类似的操作,这里省略。
经过上面的执行流程,我们得到了一个经过初始化的PeerStorage, 它从底层的engine中读取之前的raftState和applyState,或者自己初始化上述必要的内容。
Persistence & read
Storage的主要功能是为raft模块提供持久化的写入和读取功能。由于Lab2B要求我们实现PeerStorage的持久化功能,这里我们先解析其读取代码。然后根据读取操作的代码反推写入数据的格式和流程。
PeerStorage中与读取操作有关的函数有以下几个:
func (ps *PeerStorage) Entries(low, high uint64) ([]eraftpb.Entry, error);
func (ps *PeerStorage) Term(idx uint64) (uint64, error);
func (ps *PeerStorage) InitialState() (eraftpb.HardState, eraftpb.ConfState, error);其中InitialState基本上就是直接返回PeerStorage中存储的raft状态,ConfState也是直接返回Region的信息,所以这部分代码没有过多需要描述的。
Term
Term接口对于给定的一个raft index,返回该index对应entry的term。在执行时,该函数首先需要检查给定的index是否在一个合法的范围内:即它没有超出目前已知的最大的raft index,也没有被截断(compacted):
func (ps *PeerStorage) Term(idx uint64) (uint64, error) {
// Check if this index is the last compacted index
if idx == ps.truncatedIndex() {
return ps.truncatedTerm(), nil
}
// check if entries contain a range [idx, idx + 1)
if err := ps.checkRange(idx, idx+1); err != nil {
return 0, err
}
// Otherwise the index is stored in raftDB, but an acceleration is to simply return lastTerm when
// truncated term equals to lastTerm.
if ps.truncatedTerm() == ps.raftState.LastTerm || idx == ps.raftState.LastIndex {
return ps.raftState.LastTerm, nil
}
// Otherwise, read this entry from raftDB
var entry eraftpb.Entry
if err := engine_util.GetMeta(ps.Engines.Raft, meta.RaftLogKey(ps.region.Id, idx), &entry); err != nil {
return 0, err
}
return entry.Term, nil
}
// checkRange checks if specified range [low, high) is contained in this log
func (ps *PeerStorage) checkRange(low, high uint64) error {
if low > high {
return errors.Errorf("low %d is greater than high %d", low, high)
} else if low <= ps.truncatedIndex() {
return raft.ErrCompacted
} else if high > ps.raftState.LastIndex+1 {
return errors.Errorf("entries' high %d is out of bound, lastIndex %d",
high, ps.raftState.LastIndex)
}
return nil
}上面的Term实现分析了给定index的几种情况,然后分别返回错误码或者结果。这里在12行的位置有一个优化的方案,当给定的raft index确实在raft log范围内时,并不是一定要从raftKV中读取该entry。首先判断truncatedTerm和lastTerm是否相等,如果相等,那么这两个index之间的所有entry的term都是相同的,所以可以直接返回。
这里需要说明的是,上述代码在做检查时使用的lastIndex, lastTerm等数据都是保存在PeerStorage object中的,所以当PeerStorage调用持久化相关的函数时,需要实时更新这些域。
Entries
Entries函数会给定一个传入的index的range, 由[low, high)来指定,然后它将返回index在这个范围内的所有的entry。值得注意的一点是,如果这个范围是非法的(通过checkRange来检查),那么会直接返回错误码,而不是去返回low~lastIndex这个范围之间的entry。如果通过检查,Entries会在raftDB中构造一个迭代器,不断取出给定范围内的数据:
func (ps *PeerStorage) Entries(low, high uint64) ([]eraftpb.Entry, error) {
...
startKey := meta.RaftLogKey(ps.region.Id, low)
endKey := meta.RaftLogKey(ps.region.Id, high)
iter := txn.NewIterator(badger.DefaultIteratorOptions)
defer iter.Close()
for iter.Seek(startKey); iter.Valid(); iter.Next() {
item := iter.Item()
if bytes.Compare(item.Key(), endKey) >= 0 {
break
}
val, err := item.Value()
if err != nil {
return nil, err
}
var entry eraftpb.Entry
// Unmarshal is the same as deserialize, which converts a serialized bytes into a structured log entry
if err = entry.Unmarshal(val); err != nil {
return nil, err
}
// May meet gap or has been compacted.
if entry.Index != nextIndex {
break
}
nextIndex++
buf = append(buf, entry)
}
...
}由于这里startKey的构造方式与上面提到的key的raft log key的格式保持一致。但是值得注意的是在写入uint64这样的数据时采用的是big endian的方式,这样可以保证按字节比较的顺序(即raftDB比较key的方式)与index按照uint64的比较方式相同:
func makeRegionKey(regionID uint64, suffix byte, subID uint64) []byte {
key := make([]byte, 19)
key[0] = LocalPrefix
key[1] = RegionRaftPrefix
binary.BigEndian.PutUint64(key[2:], regionID)
key[10] = suffix
binary.BigEndian.PutUint64(key[11:], subID)
return key
}而写入的value则是这个entry序列化之后的结果,通过Unmarshal以及Marshal可以将一个对象在它的类型与字节数组之间进行转换。Marshal可以得到写入该raftDB的value,Unmarshal可以从读取得到的字节数组重建该数据结构。
Summary
本文梳理了TinyKV中raftstore结构的构成以及与之相关的代码,并介绍了Ticker Module和Storage Module两部分的代码。接下来会讲述Raft Module的代码,重点在于raftstore的创建与初始化,以及运行时RaftWorker是如何驱动raftstore的数据结构在时钟和外部消息输入的情况下更新raft状态。



