
XRP: In-Kernel Storage Functions with eBPF阅读笔记
XRP: In-Kernel Storage Functions with eBPF阅读笔记
Introduction
本文将介绍一篇OSDI2022年的论文: XRP: In-Kernel Storage Functions with eBPF,在这篇论文中,作者利用Linux Kernel提供的BPF(Berkeley Packet Filter)机制将用户态程序的部分逻辑移动到Device Driver层次,从而减轻了传统的Linux Storage软件栈的开销,提升了一些存储系统在Linux系统上的性能表现。
Background & Motivation
Linux系统的存储软件栈
Linux系统的存储软件栈自上而下包括了:用户态程序,文件系统层(又分为虚拟文件系统与硬件文件系统),块设备层(BIO Layer), 设备驱动层(Device Driver Layer)以及最后的存储设备层(Device Layer)。上述层次中,除了设备层之外的层次都由软件代码构成,为上层提供一定的抽象接口。例如文件系统向用户程序提供了文件这一抽象概念;块设备为文件系统提供了统一的硬件线性地址抽象;设备驱动层为块设备层提供了硬件的物理模型抽象。下图展示了一个简化的Linux存储软件栈
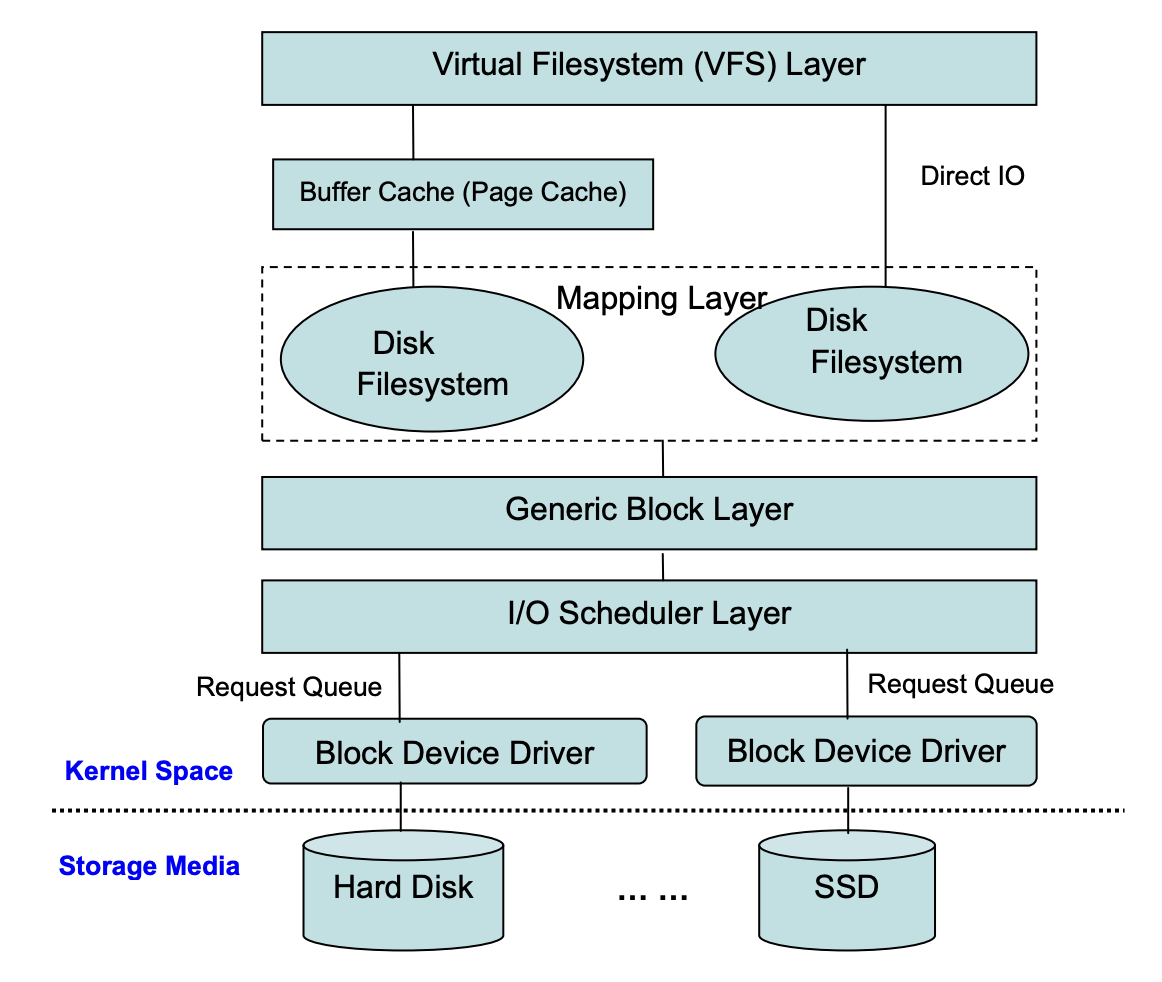
因此我们可以看到,对于一个简单的write文件操作,数据需要经过多层内核层次,最终才能到达底层的存储设备。事实上,操作系统采用这样的层次设计是有一定的道理的,文件系统层次对用户提供了文件这一有效和直观的抽象;BIO层次提供了块设备的抽象,使得任何不同型号的底层存储设备都有统一的使用接口,提供了扩展性。尤其是在很多年之前,存储设备都是慢速的磁盘,BIO层次可以将一些分离的IO请求找机会拼接为顺序读写,从而提升性能。这些软件优化对于当时的慢速设备是比较有效的,所以Linux的存储软件栈也一直延续至今。
存储软件栈成为性能瓶颈
这是本文的研究动机之一,上面已经介绍过多层次的Linux存储软件栈。对于慢速设备而言,这些软件栈的开销比起存储设备的访问开销占比较小。但是对于高速的存储设备而言,软件栈开销占比会成为一个不可忽视的因素:

在本文所做的实验中512B的随机读操作中,结果显示软件栈的开销已经达到了整个操作的50%。
为了解决这个问题,一些方法被提了出来:例如直接Bypass Kernel,应用程序绕过Linux Kernel直接读写底层设备,SPDK就提供了这样的工具。但是采用bypass kernel的方法会有以下问题:
- 系统的安全性难以保证。如果所有应用都直接操作裸设备,那很难分得清谁使用哪部分,哪些部分该读写哪些部分不该读写。
- 浪费CPU资源。这是因为用户态程序不能响应中断,只能通过轮训IO寄存器状态的方式来获知一个IO操作是否完成。轮训显然会造成CPU资源的浪费。
所以本文提出了一种利用Kernel的机制来发起IO请求,但是尽量避免执行完整的IO软件栈。
BPF机制
BPF全称为Berkeley Packet Filter, 最早于1992年出现在Berkeley大学发表的论文The BSD Packet Filter: A New Architecture for User-level Packet Capturetps中。BPF机制最开始的目的是为了方便对网络数据的分析,当时的一些网络分析应用,如网络流量监控程序等都是运行在用户态,如果需要对内核的网络数据包进行分析则需要使用系统调用将内核的网络数据包拷贝到用户态。BPF的最初设计是在允许在内核态对数据包执行用户指定的操作,然后由用户指定的逻辑来决定是否接受这个包。
从Linux 3.18版本开始,Linux系统支持了eBPF(Extended BPF), 不仅仅只局限于上面的对网络包进行计算的过程。eBPF允许用户植入自行定义的一些钩子函数,这些函数会在某些特定事件发生时会调用。而调用的过程全部发生在内核态,从而减少了内核态和用户态之间的数据拷贝。
利用BPF机制绕过部分IO软件栈
类似于使用cBPF(Classic BPF, 在eBPF出现之后,最早的BPF机制被称为cBPF)来过滤无用的软件数据包。这篇论文考虑使用eBPF来过滤不需要的内核态到用户态的数据拷贝。论文提出了两个典型的使用场景来说明何为不必要的数据拷贝:
- B+Tree的搜索操作:对一个B+Tree索引进行搜索需要从根节点不断搜索每个中间节点,对每个中间节点的数据进行一定的解析找到下一层的中间节点。最后定位到叶节点。这个过程需要的系统调用次数正好为树的高度,但实际上在搜索的过程中一个节点的数据被解析之后就没用了,没有必要将其拷贝到用户态。拷贝到用户态仅仅只是因为我们需要用户态代码解析它。
- 链表的遍历操作:和B+Tree的搜索一样,读取一个节点只是为了知道下一个节点在哪。
很显然,上述操作的行为都是:中间操作-> 最终结果的模式。中间操作需要在用户态完成,造成较大的数据拷贝开销。而BPF机制可以将部分逻辑代码交给内核执行,从而减少这之间的数据拷贝开销。
一个问题是,在哪个层次利用eBPF植入用户态代码。Linux的IO软件栈包括了以下层次:
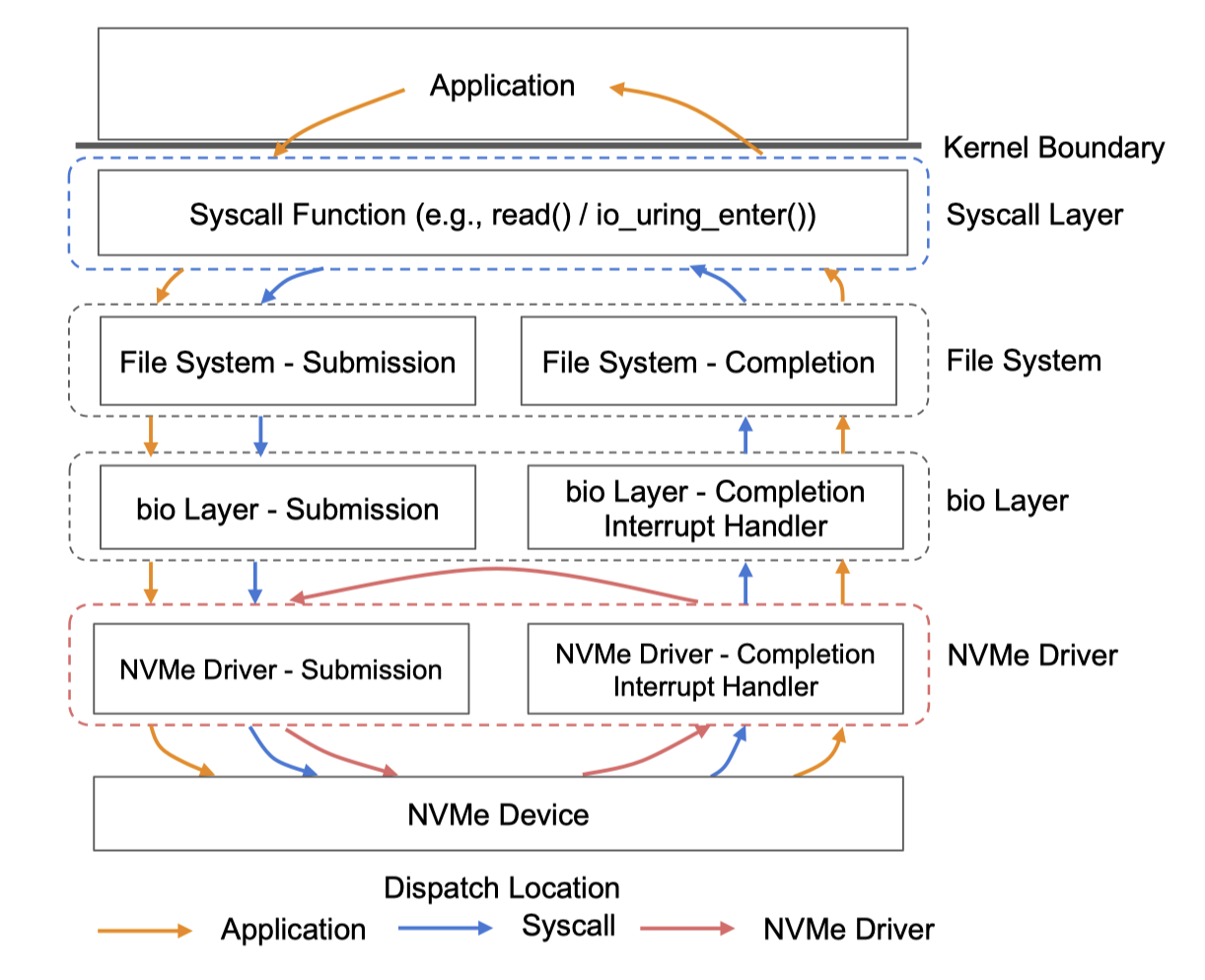

不难分析,越靠近设备层次,数据避免向上传递的层次就越多,性能就会越好。作者用测试数据说明了这一点,当用户代码通过BPF植入到Driver层时,加速比达到了接近两倍,几乎是避免了软件栈的开销。但是越靠近硬件层次,意味着要做的细致化管理也就越多,这也是本文在实现上的考虑重点。这项工作考虑将BPF函数挂载到driver层。
Design & Implementation
Design Principle
这篇论文基于BPF机制提出了XRP框架,主要目的是减少对于on-disk的data structure执行搜索操作时的IO软件栈开销。也就是,用户将自己实现的用户态代码(BPF hook)通过XRP框架提供的挂载函数挂载到内核中,然后通过XRP提供的系统调用来执行一次read操作。在这个read操作中,首先被读取的数据会被调用用户自己注册的BPF函数,然后BPF hook会根据解析结果给设备发起更多IO请求(被称为resubmission),直到最后BPF hook判定可以返回给用户。
XRP框架存在如下限制:
- 每次IO请求只能处理一个文件。
- 磁盘上的数据结构必须保证相对稳定。
- XRP框架不能支持写操作,也就是对设备的写还是需要经过传统的系统调用软件栈。
Challenge
尽管思想很朴素,但XRP实现上有许多值得注意的细节:
- XRP的resubmission在BPF hook代码中使用的是逻辑块地址,将其转换成物理设备地址需要文件系统层的元数据,但resubmission发起的时机是在driver层,无法获知文件系统信息。
- 如何对同一个文件的并发读写操作?如果在一个读操作resubmission的时候,有一个并发的写操作修改了文件数据,读操作能否读到正确的数据。
其中,前一个问题被称为address translation问题,后一个问题被称为concurrency control问题。
Implementation
Address translation
XRP框架通过在一次read请求中保存了一个该文件对应的inode指针来确保resubmission时能获知地址翻译必要的信息,这部分数据被称为metadata digest。
XRP框架实现了两个函数:
void update_mapping(struct inode* inode);
void lookup_mapping(struct inode* inode, off_t offset, size_t len, struct mapping * result);这里的mapping是指从块设备的逻辑块号到物理块号的映射。当resubmission一个IO请求时,BPF hook会在一个context中写入下一次要读取的逻辑地址,然后XRP框架通过读取inode对应的mapping来将逻辑地址翻译为物理地址。
而文件系统如果需要修改映射,则调用update_mapping来更新对应的extent tree。
Concurrency Control
这部分是关于mapping的concurrency control,一个resubmission的read请求可能会与另一个在该文件进行写入的操作在extent tree上发生读写冲突。为了解决这个问题,作者使用了类似OCC的方式,对extent tree维护一个version number,在读取数据前后分别对比version number是否发生了修改。
Case Study
Programming Interface
XRP框架为用户提供了两个接口进行使用:
int bpf_prog_load(const char* file, enum bpf_prog_type type,
struct bpf_object** pobj, int* prog_fd);
int read_xrp(int fd, void* buf, size_t count, off_t offset, int bpf_fd,void* scratch);第一个函数用于注册用户自己编写的BPF hook,该函数会在drvier层一次IO请求完成时被调用。这个BPF hook会根据读到的数据决定继续发起IO请求还是返回给用户。注册完成后,会返回这个hook的唯一标识符:prog_fd。
第二个函数read_xrp类似于一个read的系统调用,前四个参数与read相同,bpf_fd用于标识在该read过程中哪个BPF hook被使用,scratch用来存储某些上下文信息,例如在一个B+Tree的key搜索过程中,该数据可以被用于存储目标key的值。
BPF hook需要具有以下函数原型:
struct bpf_xrp {
// Fields inspected outside BPF
char* data;
int done;
uint64_t next_addr[16];
uint64_t size[16];
// Field for BPF function use only
char* scratch
};
uint32_t BPF_PROG_TYPE_XRP(struct bpf_xrp* ctxt);也就是用户自己编写的BPF hook函数读取一个bpf_xrp结构体,这个结构体包含了上一次IO的结果, 存储在data中。用户的代码逻辑会解析data,然后将下一次要读取的IO数据地址写入到next_addr和size中。done用于表示是否要返回给用户态。
一个B+Tree搜索的例子

上图展示了作者自己基于XRP框架实现的一个B+TreeKV中搜索过程的例子。为了简单起见,作者规定所有的key的大小都为8B,value的大小都为64B。B+Tree被存储在单独的文件中。上述代码很好理解,这里不再赘述。
Evaluation
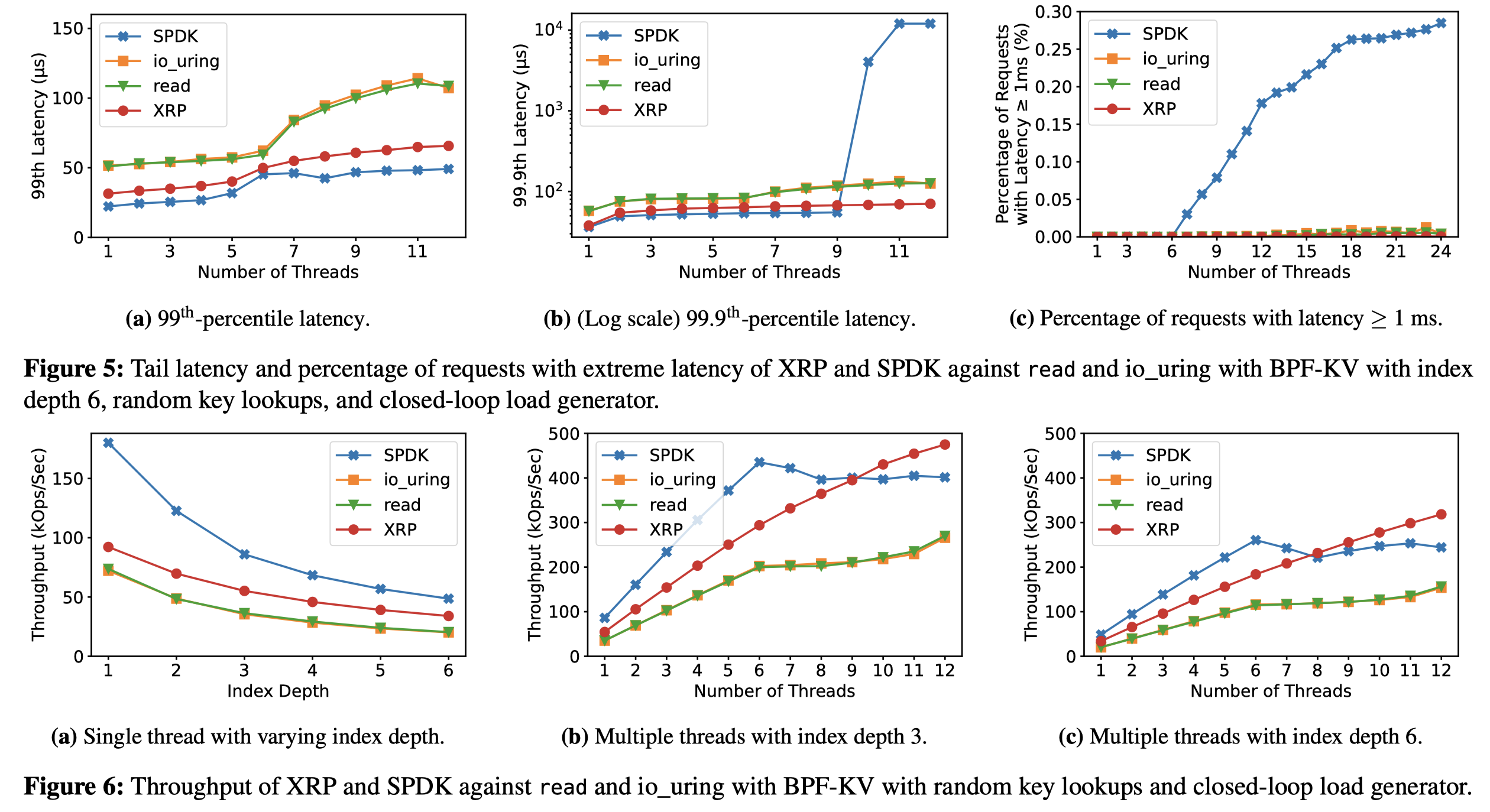
作者利用XRP框架实现了BPFKV, 即一个B+Tree作为索引的简单key-value存储引擎。以及另一个使用XRP对WeiredTiger进行优化的存储引擎。实验的对比对象包括SPDK,普通的read系统调用,以及io_uring。
Conclusion & Thinking
这篇论文基于BPF机制实现了XRP框架,用于将部分逻辑代码offload到内核执行,从而减少了从内核拷贝到用户态的IO软件栈开销。但正如论文作者自己所说,这项工作也有一些局限性。例如XRP框架完全不支持写操作,对于一些Read-Modify-Write的场景不会太好。而这种场景是有的,例如数据库中SQL的update操作可能需要读上来一些record,然后根据某些列的值更新或不更新这些列,然后再写回设备。如果能在XRP中加入写的支持就能适应这种场景。
另一个在读这篇文章时的问题是对论文中提到的concurrency control没有完全理解。如果读操作是类似于read那种读,那么在第一次读的时候就会锁住文件系统中的inode, 即使有后续的写操作也不会有读写冲突的情形。那么论文提出的一系列并发控制在文件系统层就能避免了,没有必要引入额外的机制。所以这里我猜测作者实现的xrp_read只有第一次read是线程安全的,后续的resubmission的可能会和其他write操作并发执行,因此需要额外的并发控制机制。



