
LevelDB阅读笔记:key相关数据结构
LevelDB中key相关的数据结构
LevelDB内部以及提供给用户的接口使用多种数据结构来表示不同的key,每种key都有自己的内部结构以及含义。其大致关系如下图所示:
Slice
Slice意为切片,即对字节流一部分的引用。此概念在诸如Python等高级语言中是语言内置特性。在LevelDB中,Slice的作用是引用字符串以减少在传递字符串数据时导致的copy开销。Slice被定义在include/leveldb/slice.h中,是暴露给外界使用的公共类。
Slice由于只提供对字节流的引用,本身不负责对数据的管理,所以其包含的数据成员相对简单:仅包含引用字节流的开始位置以及引用的大小
class LEVELDB_EXPORT Slice {
public:
// Create an empty slice.
Slice() : data_(""), size_(0) {}
// Create a slice that refers to d[0,n-1].
Slice(const char* d, size_t n) : data_(d), size_(n) {}
// Create a slice that refers to the contents of "s"
Slice(const std::string& s) : data_(s.data()), size_(s.size()) {}
// Create a slice that refers to s[0,strlen(s)-1]
Slice(const char* s) : data_(s), size_(strlen(s)) {}
// Intentionally copyable.
Slice(const Slice&) = default;
Slice& operator=(const Slice&) = default;
private:
const char* data_;
size_t size_;
}对应的,Slice的构造函数也提供了从多种字符串类型构造的手段:
- 默认:空引用,
size_为0 - 显式指定引用范围:
const char* d, size_t n - C++的
std::string和C风格的字符串(指以'\0'结尾的字符串)
另一方面,Slice的作用的是提供引用以简化拷贝开销,因此Slice不应该对其引用的字节流进行修改,也不应该对其引用的字节流进行资源释放等操作。基于这一原则,Slice的成员函数只对Slice本身的data_和size_进行修改,针对引用字节本身,只会返回常量或常量引用。
// Return a pointer to the beginning of the referenced data
const char* data() const { return data_; }
// Return the length (in bytes) of the referenced data
size_t size() const { return size_; }
// Return true iff the length of the referenced data is zero
bool empty() const { return size_ == 0; }
// Return the ith byte in the referenced data.
// REQUIRES: n < size()
char operator[](size_t n) const {
assert(n < size());
return data_[n];
}
// Change this slice to refer to an empty array
void clear() {
data_ = "";
size_ = 0;
}
// Drop the first "n" bytes from this slice.
void remove_prefix(size_t n) {
assert(n <= size());
data_ += n;
size_ -= n;
}
// Return a string that contains the copy of the referenced data.
std::string ToString() const { return std::string(data_, size_); }
// Three-way comparison. Returns value:
// < 0 iff "*this" < "b",
// == 0 iff "*this" == "b",
// > 0 iff "*this" > "b"
int compare(const Slice& b) const;
// Return true iff "x" is a prefix of "*this"
bool starts_with(const Slice& x) const {
return ((size_ >= x.size_) && (memcmp(data_, x.data_, x.size_) == 0));
}上述设计原则表现在operator[]的实现上,它并没有像其他的诸如vector之类的数据结构返回对数据的引用,而是返回了值拷贝。由于上述成员的实现都非常直接,代码注释也很完善,这里不再赘述。
仅看到Slice类,我的感悟就是建模在OOP编程中的重要性。每个类的具体作用,接口,以及对资源的管理都必须明确定义才能使得软件系统协调运行。当时在自己写key-value store系统的时候也想自己造轮子实现一个类似Slice的类,但由于对其定位和功能不明确,导致又想要功能又想要性能,最终的结果就是非常冗杂,其表现行为也没有良好的定义,使得其他类在使用该类时需要付出额外的代码代价。
InternalKey
InternalKey是LevelDB内部使用的key,它是用户key(即简单的字节流),SequenceNumber,以及ValueType的聚合,或者说是序列化过程。它通过一个std::string rep_来保存上述数据,并维护该资源的创建与管理,因此一个InternalKey对象是值语义的。
一个InternalKey保存的上述数据格式如下:
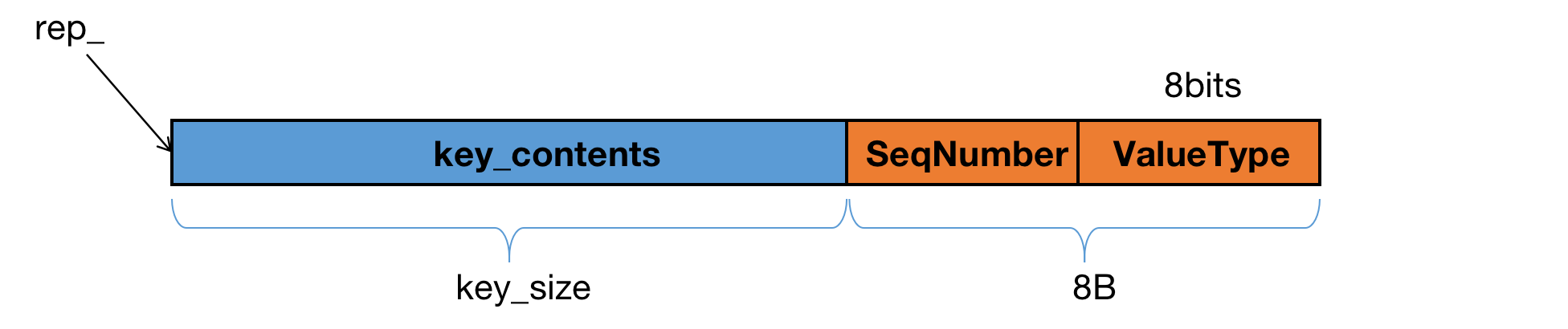
class InternalKey {
private:
std::string rep_;
public:
InternalKey() {} // Leave rep_ as empty to indicate it is invalid
InternalKey(const Slice& user_key, SequenceNumber s, ValueType t) {
AppendInternalKey(&rep_, ParsedInternalKey(user_key, s, t));
}
std::string DebugString() const;
};InternalKey的构造函数参数包含了组成其的三个部件:用户key,该key对应的SequenceNumber, 该key对应的ValueType(Delete or Insert)。其构造函数将这三个部分序列化到底层存储std::string rep_中。(这里的rep_可能是replication的简写,这也说明了InternalKey本身的值语意)
这里通过一个AppendInternalKey的函数执行了上述序列化过程,该函数将一个ParsedInternalKey对象指代的数据序列化到一个std::string中。具体流程在AppendInternalKey中,按照上图的序列化格式执行,这里不再赘述。
InternalKey提供了一对函数实现与Slice的相互转换:DecodeFrom, Encode,具体内容参考源代码。
此外,InternalKey提供了从其中获得user_key的成员函数:
class InternalKey {
public:
Slice user_key() const { return ExtractUserKey(rep_); }
}
// Returns the user key portion of an internal key.
inline Slice ExtractUserKey(const Slice& internal_key) {
assert(internal_key.size() >= 8);
return Slice(internal_key.data(), internal_key.size() - 8);
}user_key返回一个引用InternalKey内部保存的user_key的Slice对象,因此使用该函数的返回值时必须保证原有的InternalKey的生命周期。
ParsedInternalKey
ParsedInternalKey是一个InternalKey的组成部分的三元组:
struct ParsedInternalKey {
Slice user_key;
SequenceNumber sequence;
ValueType type;
ParsedInternalKey() {} // Intentionally left uninitialized (for speed)
ParsedInternalKey(const Slice& u, const SequenceNumber& seq, ValueType t)
: user_key(u), sequence(seq), type(t) {}
std::string DebugString() const;
};设计这个类的原因是:
InternalKey只是一个字符串,不具有结构上的意义,如果用户想知道一个InternalKey对应的SequenceNumber或者ValueType则需要手动进行解析。InternalKey只提供了user_key的访问接口,没有提供其他两个部分的访问接口。
ParsedInternalKey与InternalKey(所表示的字符串)之间的转换关系由两个函数实现:
// InternalKey(Slice) -> ParsedInternalKey
inline bool ParseInternalKey(const Slice& internal_key, ParsedInternalKey* result);
// ParsedInternalKey -> InternalKey(rep_)
void AppendInternalKey(std::string* result, const ParsedInternalKey& key);上面两个函数只是基本的序列化与反序列化的过程,这里不展开说明,详细过程可以阅读源码。
LookupKey
LookupKey是LevelDB内部用于数据查找的key,即user_key + sequenceNumber的结合。从一个LookupKey可以方便地得到该key对应的user_key以及internal_key等形式。
// A helper class useful for DBImpl::Get()
class LookupKey {
public:
// Initialize *this for looking up user_key at a snapshot with
// the specified sequence number.
LookupKey(const Slice& user_key, SequenceNumber sequence);
LookupKey(const LookupKey&) = delete;
LookupKey& operator=(const LookupKey&) = delete;
~LookupKey();
// Return a key suitable for lookup in a MemTable.
Slice memtable_key() const { return Slice(start_, end_ - start_); }
// Return an internal key (suitable for passing to an internal iterator)
Slice internal_key() const { return Slice(kstart_, end_ - kstart_); }
// Return the user key
Slice user_key() const { return Slice(kstart_, end_ - kstart_ - 8); }
private:
// We construct a char array of the form:
// klength varint32 <-- start_
// userkey char[klength] <-- kstart_
// tag uint64
// <-- end_
// The array is a suitable MemTable key.
// The suffix starting with "userkey" can be used as an InternalKey.
const char* start_;
const char* kstart_;
const char* end_;
char space_[200]; // Avoid allocation for short keys
};LookupKey的内容包含了三个字段:
klength+8的Varient32编码。- 一个长度为
klength的字节数组,用于表示user_key tag域是SequenceNumber和ValueType组成的8B字段,但是这里只使用了SequenceNumber
LookupKey的优化方式是,对于小key, 即编码后长度不超过200的,使用该结构自带的字符数组,否则使用动态分配的数组,从而避免动态分配产生的开销。但是如果使用动态分配的数组也可能造成局部的200字节数据的浪费。至于200到底是怎么来的,应该是经过了多次调优发现的,200应该能满足在大部分情况下key的存储,因为key-value store的场景中,大部分key的长度都比较小。
这里有个疑惑的地方:在上述代码注释中,start_指向的地方存储了klength的Varient32编码,但是在LookupKey的构造函数中可以发现,这个地方的代码写法是:
start_ = dst;
dst = EncodeVarint32(dst, usize + 8);因此存储的是user_key + tag的长度。
Comparator
leveldb是一个key-value store存储引擎,更具体地说,LevelDB提供有序key存储以及多版本的存储,这是出于BigTable的要求。由于有序key的存在,系统必须提供对应的比较函数用于确定给定key的全序关系;同时,leveldb允许用户定义自己的key comparator,从而使得leveldb获得更加广泛的应用场景。
Comparator基类
Comparator抽象基类定义在comparator.h文件中(include/leveldb/comparator.h),作为开放接口之一提供给leveldb用户。该类提供了最基本comparator接口,即按照自定义顺序对两个Slice进行比较,返回该comparator名称等。此外,还提供了两个高级函数,用于leveldb内部:
class LEVELDB_EXPORT Comparator {
public:
virtual ~Comparator();
// Three-way comparison. Returns value:
// < 0 iff "a" < "b",
// == 0 iff "a" == "b",
// > 0 iff "a" > "b"
virtual int Compare(const Slice& a, const Slice& b) const = 0;
virtual const char* Name() const = 0;
// Advanced functions: these are used to reduce the space requirements
// for internal data structures like index blocks.
virtual void FindShortestSeparator(std::string* start,
const Slice& limit) const = 0;
virtual void FindShortSuccessor(std::string* key) const = 0;
};Compare是核心接口,也是实现key有序的关键,用户将在该函数中定义自己的比较逻辑以实现三路比较。其返回值是一个整数,通过与0比较来说明比较的两个key之间的顺序。FindShortestSeparator和FindShortSuccessor先省略不管。
默认比较模式:ByteWiseComparatorImpl
ByteWiseComparator将两个Slice对象视为字符流并进行比较,比较的逻辑是:
- 如果一个字符流是另一个字符流的前缀,则较长的那个字符流更大。
- 否则,两个字符流一定在某个位置不同,在该位置字符更大的那个
Slice被认为更大
这实际上就是Slice::compare的逻辑,ByteWiseComparatorImpl也是直接调用的Slice的compare函数:
class BytewiseComparatorImpl : public Comparator {
public:
BytewiseComparatorImpl() = default;
const char* Name() const override { return "leveldb.BytewiseComparator"; }
int Compare(const Slice& a, const Slice& b) const override {
return a.compare(b);
}
}LevelDB系统内部,或者用户可通过调用ByteWiseComparator来获得一个默认的ByteWiseComparator对象,这里运用了单例模式:
const Comparator* BytewiseComparator() {
static NoDestructor<BytewiseComparatorImpl> singleton;
return singleton.get();
}关于单例模式的更多信息,可以参考:wiki
InternalKey比较模式:InternalKeyComparator
InternalKeyComparator定义在dbformat.h中。InternalKeyComparator对两个InternalKey进行比较,比较的顺序是:
- 先比较
InternalKey包含的user_key,user_key大的就更大 - 如果
user_key相同,则比较SequenceNumber,SequenceNumber大的就更大
因此,InternalKeyComparator内部必须保存一个comparator对象用于比较user_key的大小:
class InternalKeyComparator : public Comparator {
private:
const Comparator* user_comparator_;
public:
explicit InternalKeyComparator(const Comparator* c) : user_comparator_(c) {}
const char* Name() const override;
int Compare(const Slice& a, const Slice& b) const override;
}
int InternalKeyComparator::Compare(const Slice& akey, const Slice& bkey) const {
// Order by:
// increasing user key (according to user-supplied comparator)
// decreasing sequence number
// decreasing type (though sequence# should be enough to disambiguate)
int r = user_comparator_->Compare(ExtractUserKey(akey), ExtractUserKey(bkey));
if (r == 0) {
const uint64_t anum = DecodeFixed64(akey.data() + akey.size() - 8);
const uint64_t bnum = DecodeFixed64(bkey.data() + bkey.size() - 8);
if (anum > bnum) {
r = -1;
} else if (anum < bnum) {
r = +1;
}
}
return r;
}上面的anum和bnum是SequenceNumber和ValueType的聚合,但是由于SequenceNumber在高56位,所以直接比较这两个值也相当于比较SequenceNumber了。
总结
本节我们讨论了LevelDB内部几种与key相关的数据结构,包括几类key本身以及对应的comparator。通过阅读源码我们获得了以下启发:
- 明确类的行为与语意;例如
Slice只提供常量引用功能,不管理资源。InternalKey和LookupKey均需要持有数据的拷贝。通过在写代码前明确这些类的功能与内存所有权等信息,可以使得代码更加明确。 - 对于从某个结构化数据序列化得到的字符串,需要提供一个“解析器”方便用户获得各个部件的信息。例如:
InternalKey与ParsedInternalKey - 如果一个类需要动态内存分配,可以考虑在其内部通过保留一定大小的空间来避免动态内存分配;例如
LookupKey。但是也需要考虑此举带来的空间浪费,我相信google的工程师们一定是经过大量统计分析后才定下了200作为LookupKey保留空间的大小。 - 如果确定整个代码空间只会使用某个类的一个对象,可以考虑使用单例模式。(有点类似于全局变量)



