
MICA Reading Notes
MICA: A Holistic Approach to Fast In-Memory Key-Value Storage
Overview
MICA is an in-memory key-value store system that enables fast Put and Get operation. In this paper, the author proposes three aspects of designing an in-memory key-value store, as follows:
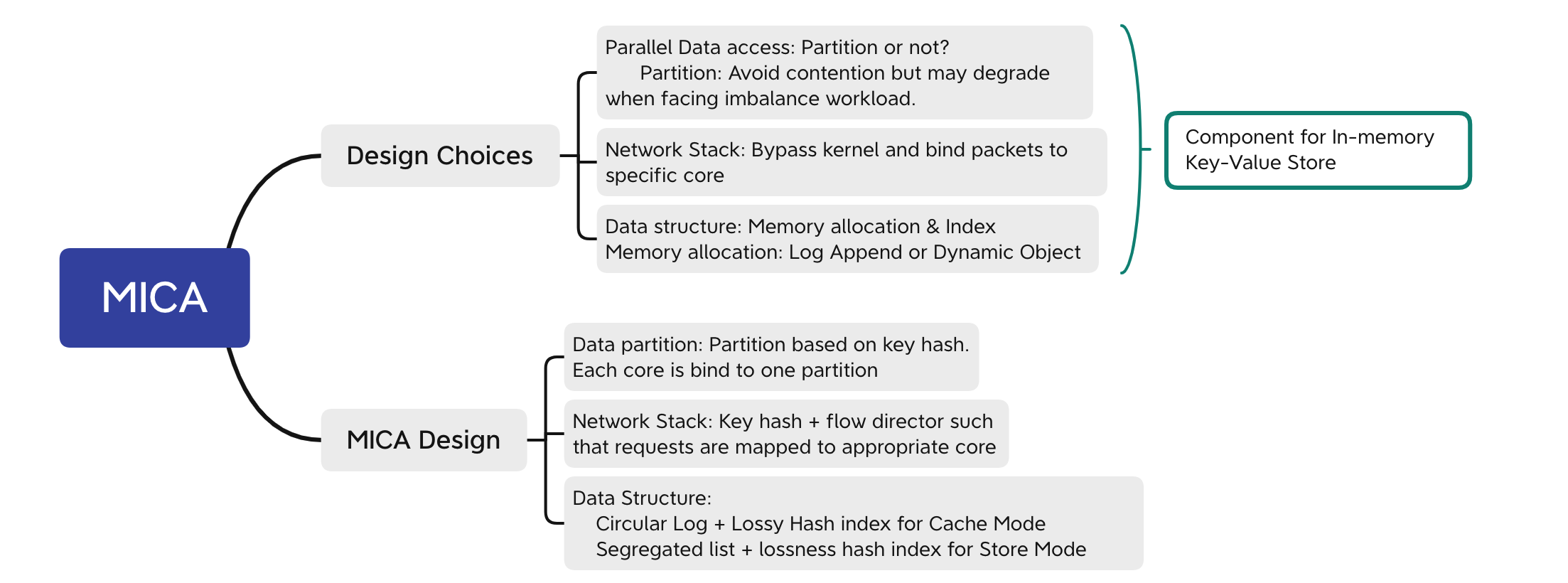
The three aspects includes:
- Use data partition or shared data replacement strategy?
- How to effectively process network request packets?
- Design data structures for fast processing requests
Based on above design aspects, the author designs and implements MICA by taking reasonable choices in these three aspects:
- MICA uses data partition to avoid access contention in shared data case.
- MICA bypass operating system kernel by directly reading from NIC.
- MICA designs circular log, lossy hash indexes for fast put and get operation.
In conclusion, this paper, as stated in the title, shows a “holistic” view of designing an in-memory key-value store, which covers data replacement, data structure and request processing.
Key-Value store design choices
Data partition or Not
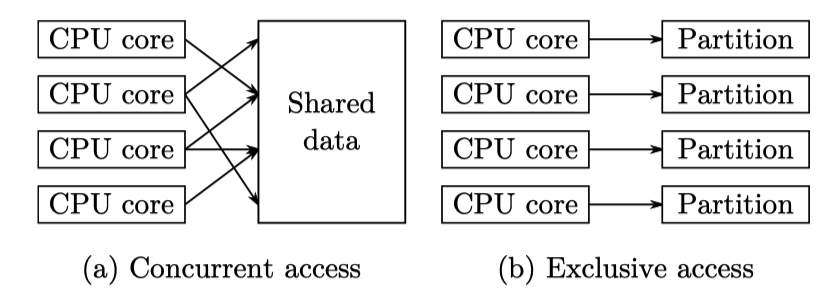
The author claims there are two modes for data placement(or access scheme, but placement often determines access mode), namely concurrent access and exclusive access.
- Concurrent access: Multiple threads access shared memory data via synchronization (mutex etc.).
- Exclusive access: Each core only accesses its local data partition.
Obviously, exclusive access avoids heavy contention of shared data, and the paper states:
Prior work observed that partitioning can have the best throughput and scalability.
However, partition strategy may face performance degrade due to imbalance workload. For example, one parition are heavily accessed while the others are not. The core binds to the frequently-accessed parition becomes the bottleneck in the whole system. In contrast, in a shared-data system, this may not become an issue since multiple cores can concurrently execute requests.
The key issue is to eliminating penalty caused by skewness by reasonably paritioning the whole data set.
Avoid network stack overhead
Conventional KV store uses socket IO for transferring data, this may cause huge network stack overhead. One way to solve this is to directly read data from NIC. However, user-level can not decide which core processes the packet. There are two levels of packet directing:
- flow-level directing: NIC hashes the header of a package and sends it to a core based on the hash value with a user-specified mapping table.
- Object-level directing: The software uses core-communication to handle a packet to another.
Data structures
There are two key components for an in-memory key-value store:
- Memory allocator for storing key-value pairs.
- Indexes for fast searching specific items.
As for memory allocator, there are two kinds of designs:
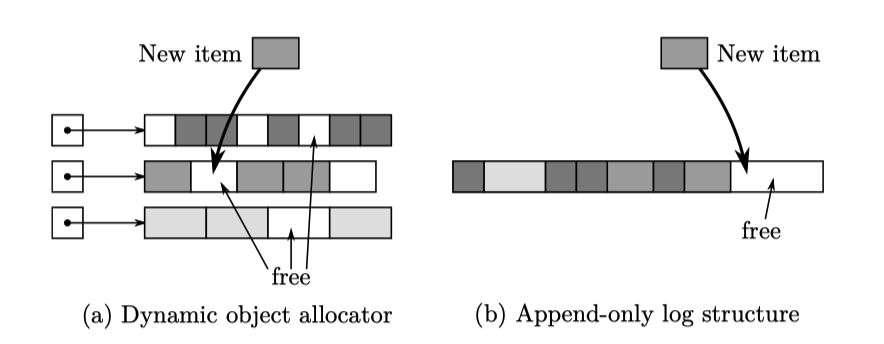
- Log-based allocator: Append key-value items to the end of the log. The garbage collection is done by moving all alive objects to a new log pool.
- Dynamic Obj allocator: This is similar to our
mallocfunction that dynamically allocates memory for objects of different size. The allocator has to track allocated memory and merge unused memory region when necessary.
Indexes are responsible for retriving a key-value pair in memory pool. So it must be both read and write fast. Hash table is a good choice for this case.
MICA designs
MICA designes includes the tradeoffs for the three aspects mentioned above. The overview of MICA is as follows:
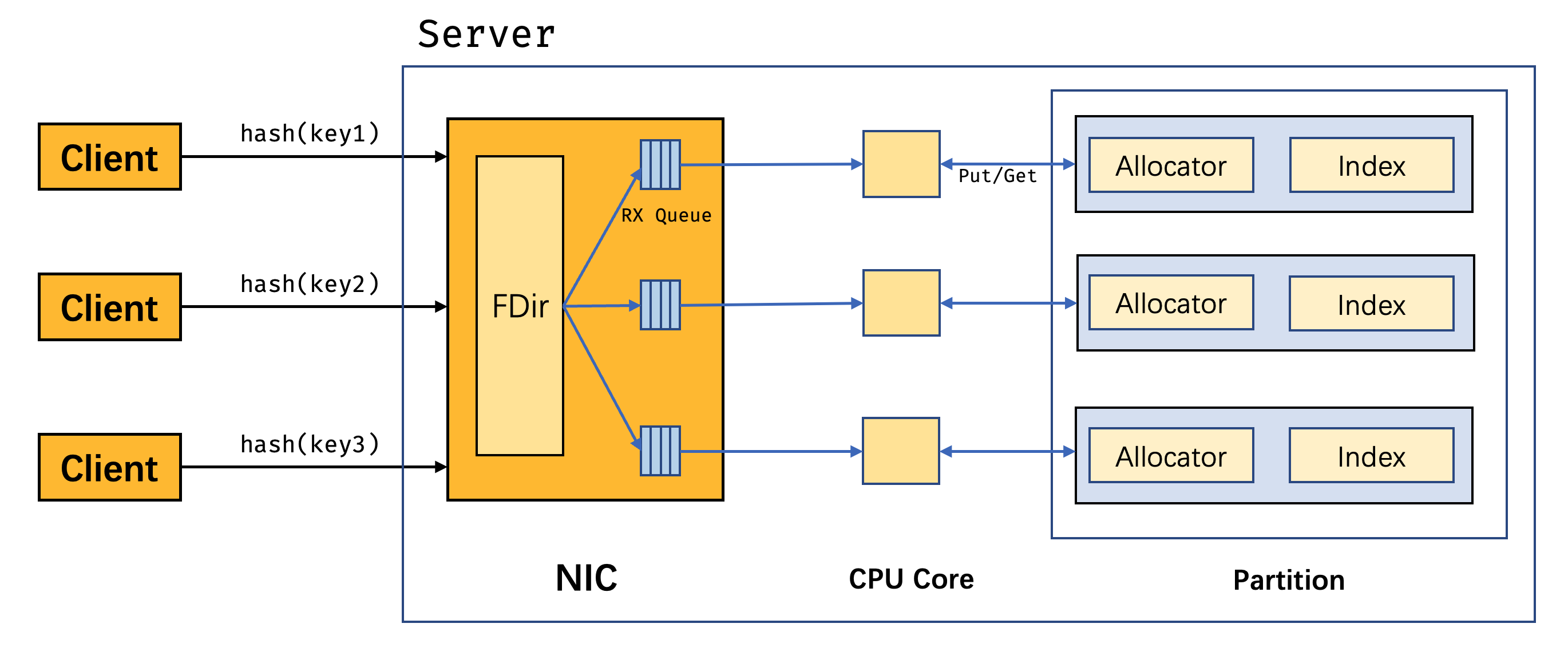
Data parition
MICA takes data parition method to achive parallel data access. The partition uses Keyhash-based partition scheme. That is: keys are divided into separate paritions based on their hash value. (Each parition occupies an equal range of hash value).
The advantage is:
Eliminate skewness since keys are distributed uniformly after a uniform hash function. The paper says:
after partitioning keys into 16 partitions, however, the most popular partition is only 53% more frequently requested than the average
The author defines two access modes under data partition strategy, namely EREW, CREW:
- EREW: Exclusive Read Exclusive Write, each core can only access its own parition, thus requires no extra synchronization.
- CREW: Concurrent Read Exclusive Write. Multiple core can read one parition but each core can only write its own partition. This enables concurrent access to avoid skewness overhead but incurs extra sychronization overhead.
Network stack overhead
MICA avoids network stack overhead by directly transferring packages from NIC.
Package direction:
- Each request packages should be handled to the partition containing the key the packages carries.
- NIC director does not understand package key and thus failed to handle the package to appropriate core
- MICA client calculates the hash value of the key and encodes it in the header of UDP package, assiting hardware to direct the right core.
Data structure
MICA can be used as a cache or key-value store. In cache mode, a inserted key-value pairs might be evicted and can not be accessed for the next Get.
Cache Mode
MICA uses circular log and lossy hash index for cache mode.
Circurlar log is basically a queue in which each element is a key-value items.
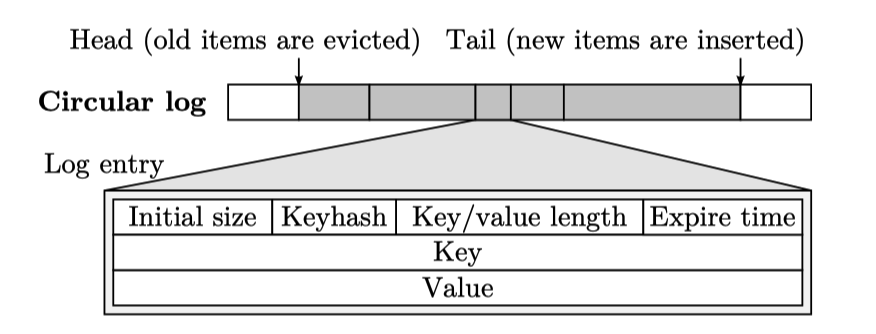
- Insertion: Append key-value items to the tail of this log.
- Updating: Find the offset of specific key, if the size is big enough to accommodate new key-value pair, then overwritten old contents, otherwise do insertion.
Insertion operation may overwritten items at head end, but this is allowed in cache semantics.
Lossy Hash index is a hash index that enables CPU cache-like evicted strategy:
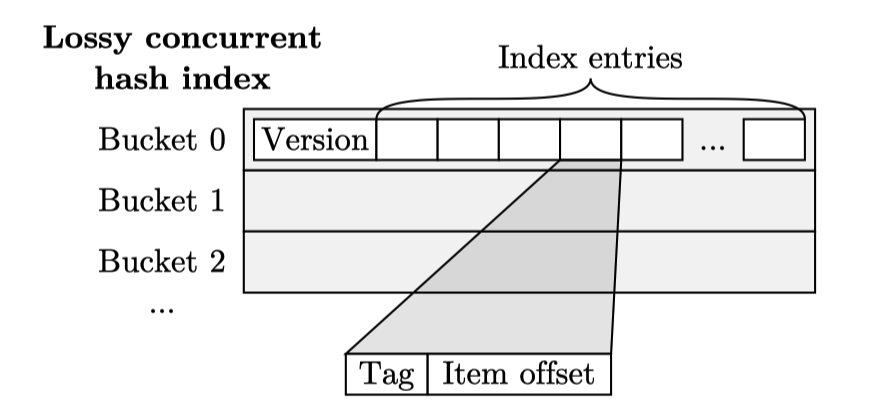
- Hash index consists of multiple buckets. Each bucket contains a fixed number of index entries.
- Each index entry contains a tag (a portion of key hash value) and offset (where key value items are stored)
- Insertion: find the target bucket and evict one item from this bucket if the bucket is full, otherwise write tag + offset at an empty slot.
- Get: Find the target bucket, compare key tag and stored tag to find match item.
Concurrent Lossy Hash Index: In CREW mode, one core might write the index while the other cores are reading it. The hash index uses optimistic locking scheme by adding a version number field to each bucket. Each operation first checks if version is even, which indicates a write is in progress, before actually modifying bucket data.
How Circular log and Lossy Hash index works together in partition?
When inserting a key-value pair into a data partition, circuclar log first makes space containg this item, then inserts coresponds item offset and tag to hash index. When inserting into hash index, one item might be evicted from the same bucket but it’s ok because of cache semantics. In addition, there is no need to reclaim related log space as incomming insertion will overwrite it and it will not be accessed since hash index has removed this item.
However, append entries to circular log may overwrite an existed item and corresponds index entry is supposed to be deleted in case dangling pointer issue. MICA solves this problem by using bigger pointer.
When deleting a key-value pair in a data partition, directly remove item in hash index.
When searching for a key-value pair, it directly searches the hash index.



