
BigTable Reading Notes
Bigtable: A Distributed Storage System for Structured Data
What is Bigtable?
The title of this paper might be a little confusing since it contains two key words “Table” and “Structured Data”. One may refer Bigtable as a distributed relational database system but it’s actually not. The paper has defined BigTable explicitly:
A Bigtable is a sparse, distributed, persistent multidimensional sorted map. The map is indexed by a row key, column key, and a timestamp; each value in the map is an uninterpreted array of bytes.
You may treat BigTable simply as a distributed sorted map but also supports structured data storage interface. It is “sparse” because it’s quite different from standard relational model:
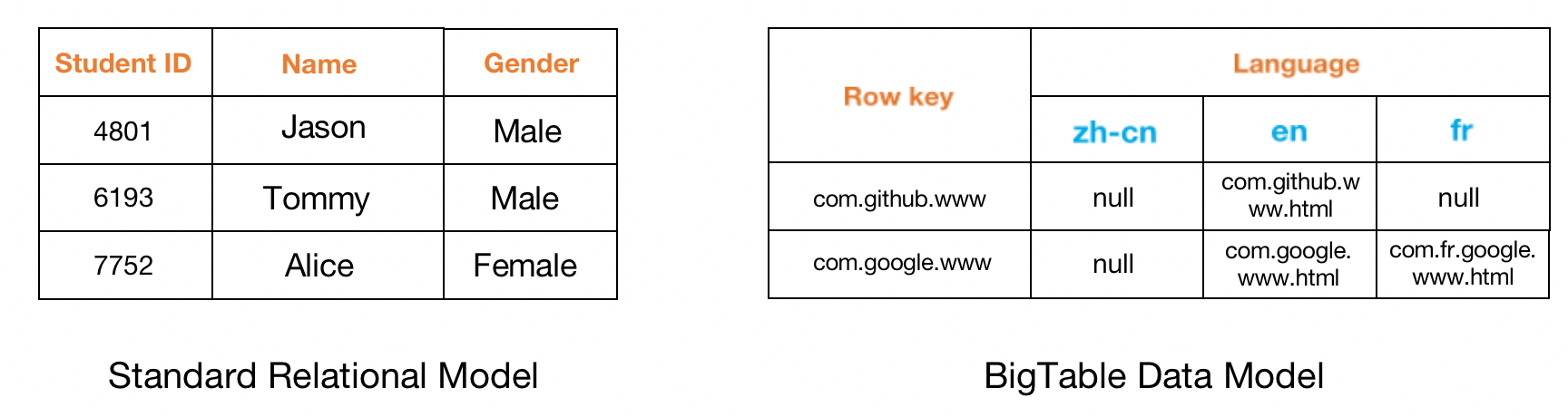
In standard relational model, each record(row) contains multiple fields(column) and typically all fields contain useful message. However, in BigTable model, each record may have or may not have a data for a specified column. Thus, it’s sparse in this sense.
Data Model
As discussed above, BigTable is basically a key-value map in the following form:
<row_key, column_key, timestamp> -> valueThe key is triple consists of row_key, column_key, timestamp.
- row_key is similar to primary key in relational model, it uniquely identifies one record. row_key is a string which has size of no more than 64KB.
- column_key is similar to field in relational model, it depicts the record’s value at speicific attribute. A column_key is specified by a column family and qualifier combination.
- Column family is a group of column keys. Just as table schema in relational model, you have to create it before storing data with column keys belong to this family. However, the difference is once the column family is created, you don’t need to explicitly create column keys within this group, instead, you add column keys into this group by dynamically inserting records.
- timestamp is for version control, it’s denoted as a 8B integer.
One example of above concepts is the webpage example in original paper:
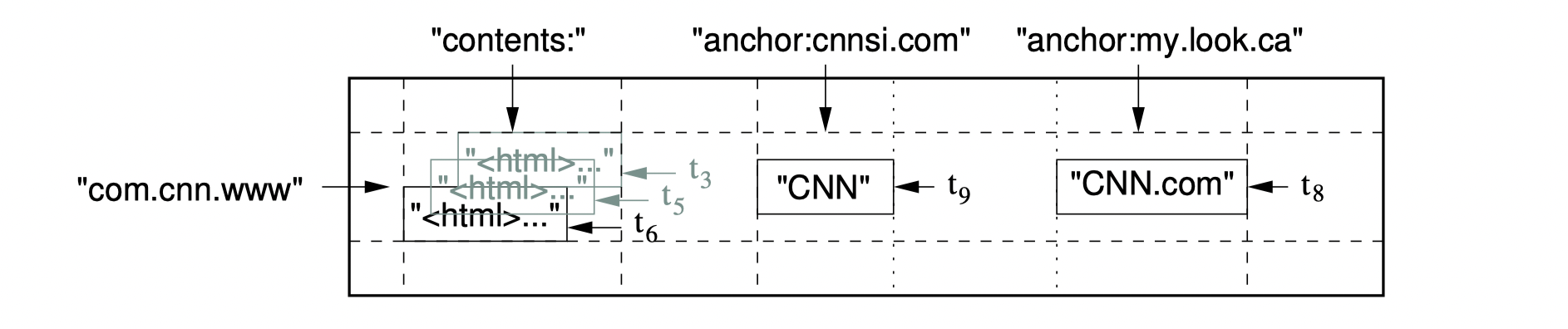
This picture depicts a logic view of a table storing webpages. The picked row, specified by row_key of com.cnn.www, has three column keys: contents, anchor:cnnsi.com, anchor:my.look.ca. Thus, this table (within view of this pic) has two column families: contents and anchor. The t3, t5, t6 specifies different version. BigTable system allows user to configure the number of versions available and automatically garbage-collect other versions.
Each triple is mapped into some value, for example:
<"com.cnn.www", "anchor:cnnsi.com", t9> -> "CNN"System Designs
Overview
Since BigTable is a distributed sorted map, there are some basic questions to ask:
- How to shard this map and distribute them among thousands of machines.
- How could a client interact with this system, for example, send read or write requests
- How to guarantee fault tolerance?
We first shows the overview structure of BigTable system to answer above questions.
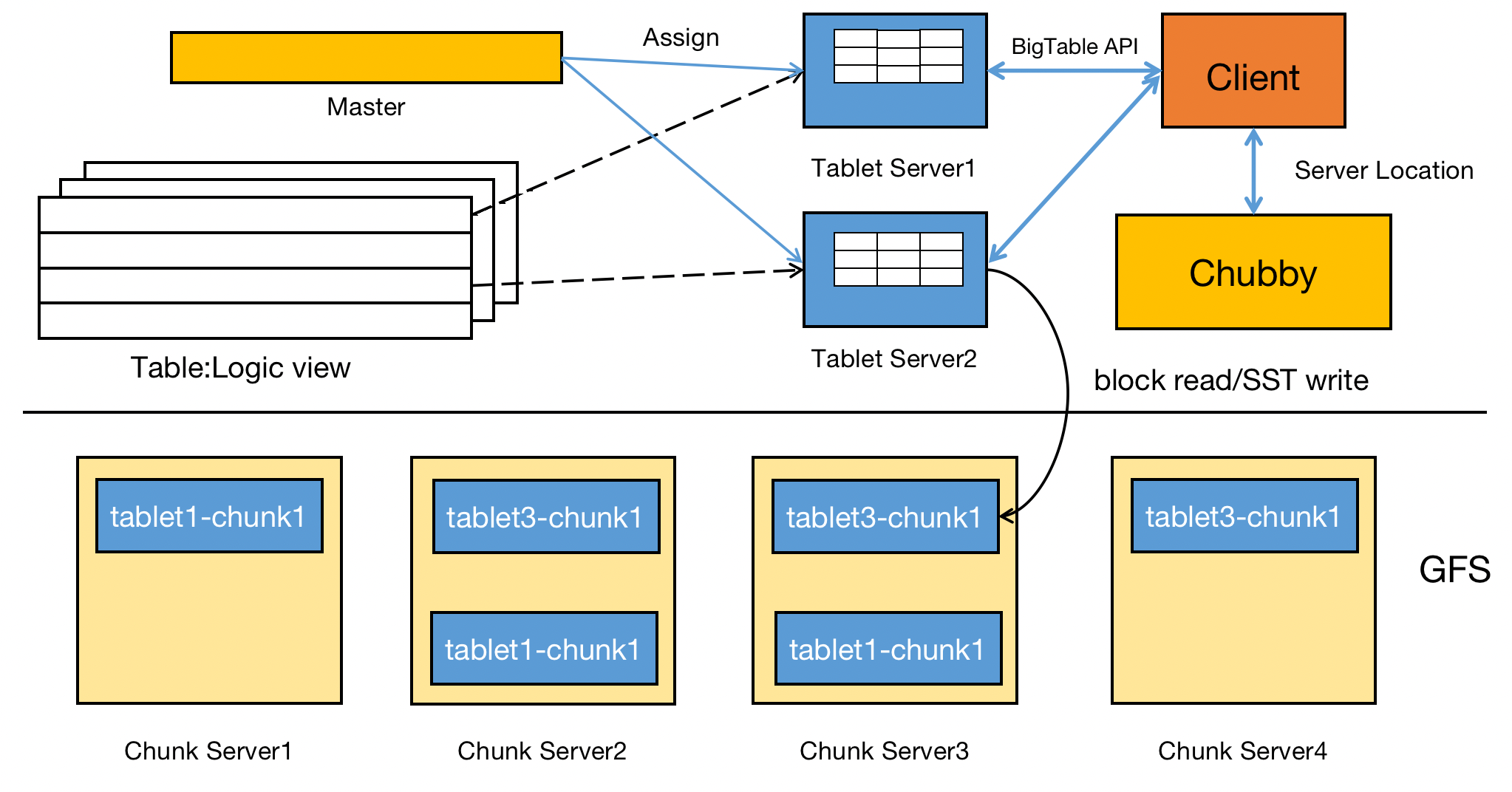
Let’s first introduce the overall structure of Bigtable. As for logic view, BigTable is a table which dynamically maintains sorted key-value map. To deploy this map among a cluster, BigTable sharded the whole table into mutliple tablets by grouping sorted row keys. According to the paper description, a tablet is the unit of distribution and load-balancing.
Different tablets are assigned to different servers to provide services. The assignment is done by master server and is managed by chubby service. Once this assignment is done, the client will ask the chubby server for the location of target tablet and then directly communicate with target tablet server.
The tablet storage depends on GFS to achive fault tolerance (Three-replicas) and high performance. BigTable uses GFS to store immutable SSTable files generated by tablet server during insertion/updating/deletion operation requested by clients. In addition, WAL (Write Ahead Log) is stored in GFS and accessed during tablet server recovery.
Expressions
We settled on this data model after examining a variety of potential uses of a Bigtable-like system
翻译:”settle on” 意为定下,这里翻译是”在检视了各种bigtable系统可能的用途之后,我们最终定下了这个数据模型“





