
MapReduce Reading Notes
MapReduce: Simplified Data Processing on Large Clusters
Overview
MapReduce: A program model and associated implementation of large data processing. It abstracts data processing into two phase: Map and Reduce. The MapReduce system itself takes full charge in system related problems, e.g. server failure, worker scheduling, which enables the user (with no experience in distributed computing) to only consider designing proper Map and Reduce function for their specific purpose.
This 2004 OSDI paper depicts MapReduce design, including the motivation and background of the propose of MapReduce system, the design and associated design extentions of MapReduce.
Background & Motivation
Google programmers used to write very complex codes for huge data process executed on cluster comprising thousands of servers. These codes have to execute their expected program logic correctly while dealing with common issues happened in any distributed systems, such as server failure, work scheduling and network transfer. However, these data process, such as sorting files of terabytes or counting words occurrances, share some common patterns(or similar execution flow).
Jeaf Dean and Sanjay Ghemawat, two genius programmers, noticed the commen patterns that hide behind these complex process. Inspired by functional programming language, they abstracted these commen execution patterns into two phase: Map and Reduce, which enables the separation between work execution logic and complex distributed system management.
Design
Map & Reduce
Users of MapReduce system are required to provide Map and Reduce function.
Map: Reading input data file and generate intermediate key-value fileReduce: Reading intermediate key-value file, and generate final output file.
The original paper provides several Map and Reduce examples of typical data processing. For more information, see the original paper.
System Design
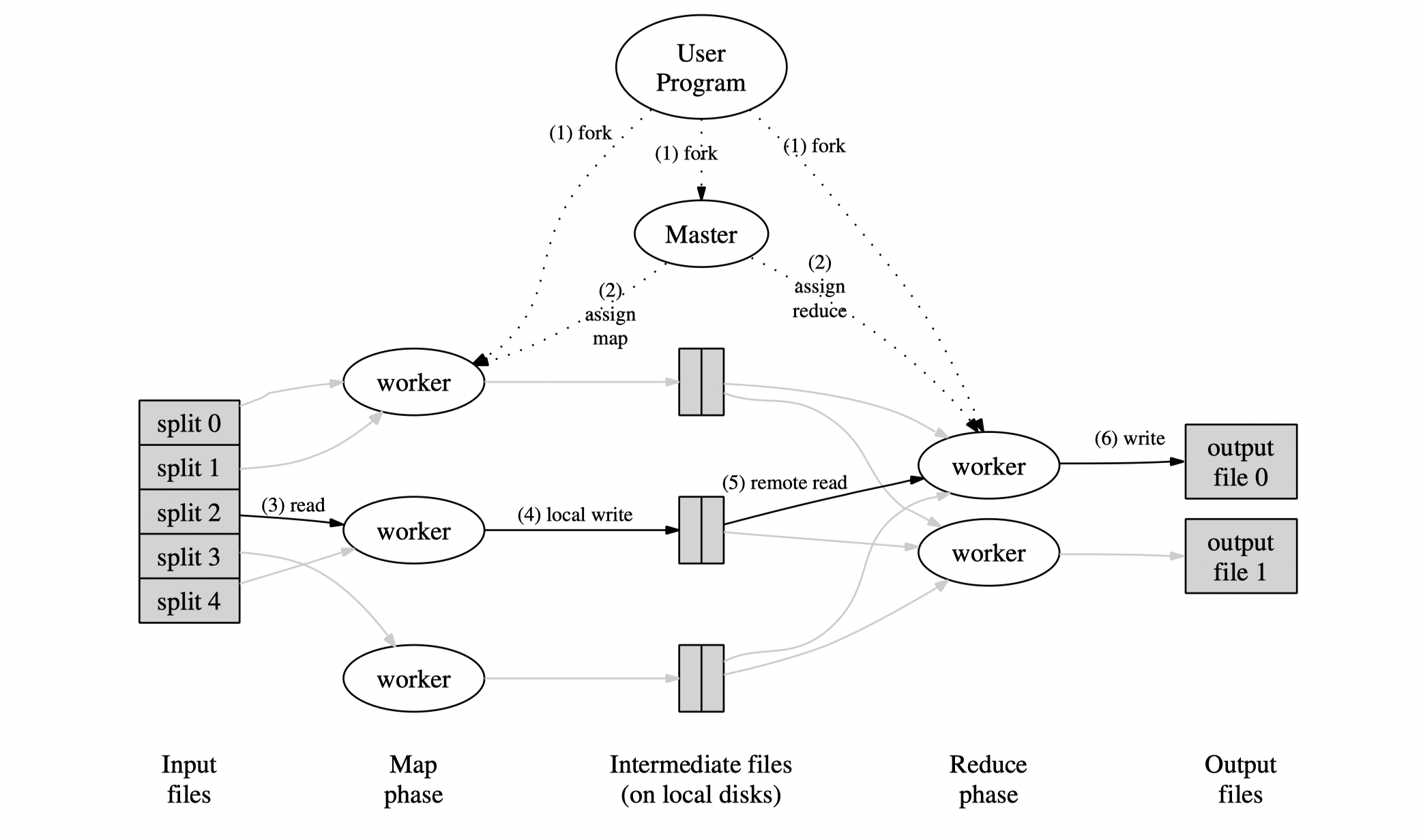
There are two kinds of machine running in MR(MapReduce) cluster, namely worker and master.
- Worker: The machine that does actual computing, one machine might execute both map and reduce tasks.
- Master: A monitor reponsible for work scheduling and worker management. In MR system, there is only one single master.
One MapReduce task execution example is as follows:
- Master splits input data file and assign these splits to each Map worker.
- Each Map worker calls
Mapfunction provided by user upon master-assigned input data file and generates intermediate key-value file. - Map worker notifies Master the assigned Map task has been finished by transferring intermediate file location to master.
- The Master schedules Reduce worker to read intermediate file contents through RPC and does Reduce task by calling
Reducefunction. - Reduce worker generates final output file as reduce task is finished.
Implementation Details & Optimizations
The basic conception of MR is simple, however, there are some implementation details:
Deal with server failure
Server failure is an ievitable problem in distributed systems, it’s same for MR system. The key point is how to detect server failure and restore it.
- Detect Failure: The master periodically pings worker to detect their liveness. The master maintains information of execution server of each assigned Map or Reduce task.
- Worker Failure: Re-execute tasks assigned to this server, no matter these tasks are finished or not.
- Master Failure: The original paper asserts single master is not likely to crash. If it does, the user has to retry the whole MapReduce task.
Partition & Shuffle
When a Map task is done, it typically generates $R$ intermediate output file, where $R$ is the number of reduce task. Partition is the process to distribute the map results of input file into different Map resultant files.
- The paper proposes using hashing modular partition scheme to achive workload balance, i.e. Each intermediate output file has similar data size.
- The paper says MR system guarantees intermediate keys are sorted within the same partition. However, no further details explains how this process is running.
Reduce Network Transfer
Network bandwidth is a main contraints for distributed systems back to 2000s. The paper cliams the whole MR system share the network in a tree hierarchy structure, i.e. Neighbour machines share the same switch, and lower level switch shares the same higher level switch. This makes each server only shares very limited network bandwidth. For example, if the root switch has a bandwidth of 1Gbits/s, while there are 32 servers in this local network, then each server could only leverage a bandwidth of 32Mbits/s.
In MR system, Master will assign Map or Reduce task to a worker that is near to the server which stores the input data file, in order to prevent unnecessary network data transfer.
However, modern MR system tends to separates MapReduce cluster from data storage cluster since they assume network is extremly fast nowdays.
Reduce long tail lantency
- In MR system, the long execution of the final Map or Reduce task(Caused by lower disk IO or CPU) will cause high tail lantency of the whole MapReduce task (See Evaluation part ).
- MR uses Backup Execution to solve this problem: Master notifies multiple workers to execute the same task individually. The first server that finishes this job will commit its results.
Additional Materials
- MIT 6.824 Lab1 requires you to implement a simplified MapReduce system and is able to execute a word counter demo.
- Hadoop: The definitive guide describes a modern MR system implementation of Hadoop MapReduce system.
Expressions
Failing that, it attempts to schedule a map task near a replica of that task’s input data
翻译:Failing that被译为“如果做不到这一点“。
Ideally, M and R should be much larger than the number of worker machines
翻译:”Ideally” 被翻译为“在理想情况下“
Users have found the counter facility useful for sanity checking the behavior of MapReduce operations
翻译:Sanity checking意为验证正确性。
The worker deaths show up as a negative input rate since some previously completed map work disappears (since the corresponding map workers were killed) and needs to be redone.
翻译:show up 意为“出现“,这里的翻译是:”服务线程的死亡(server failure)以负的输入速率的形式展现。”





