MIT6.824 Lab3A笔记
MIT6.824 Lab3A 实现笔记
MIT6.824的第三个实验要求我们在Lab2中实现的Raft基础上完成一个容灾的key-value store服务。整个实验分为两个部分,即Lab3A和Lab3B;前者要求我们在不考虑Snapshot的情况下实现这样一个key-value store的基本Put/Append/Get功能,后者则要求我们在Lab3A的基础上实现snapshot以帮助crash的kv server快速恢复状态。这里将实现Lab3A的过程中的一些问题进行记录, 但根据课程的要求,这里并不直接贴出实现代码,而仅仅提一下思路。
基本设计
课程网站上的diagram给出了整个分布式key-value store的架构:
Clerk负责接收来自Client的请求并将请求发送到Kv server上进行处理KVServer是一个本地的key-value store,其后台运行着一个raft routine来确保log entry的replication正常进行。KVServer需要对来自Clerk的读写请求进行相应的操作。
写请求的大致流程如下:
Clerk接收到Put/Append操作请求(client.go中的Put和Append接口)。Clerk将该请求通过RPC发送到leader对应的KVServer上,通过调用server.go中的KVServer.PutAppend接口。- 在Leader上,通过调用
raft库的Start接口将一条Put/Append命令加入到Raft Log中。 - 等待Leader将该Log Entry 备份到majority server之后进行commit,在apply时修改本地的kv store。
- 回复
Clerk的请求信息
读操作也是类似的流程,这里不再赘述。
上面说明了正常情况下的流程,但有些问题并没有细节的阐述:例如Clerk如何知道当前的Leader是谁;在RPC调用中,如何等待log entry提交了之后才返回等等。
实现细节问题
Leader detection
Clerk在初始情况下是不知道raft集群中谁是leader,因此它需要对每个server都发送一次RPC请求,请求调用KVServer的Start接口,并以返回值来判断该server是否为leade,该过程称为Leader Detection。课程网站中的Hints也提到,可以在Clerk中保存LeaderId, 这样下一次请求时可以直接向该Id指代的server发起请求而不用探测,从而加快操作,但需要时刻维护LeaderId的值。另一种做法是,每个Raft server保存当前的Leader的ID,当Clerk将一个请求发送到一个非Leader Server时,该Server的回复中带上其认为的LeaderId。
我的实现中采用了第一种方案,因此需要在每个RPC call结束之后将LeaderId设置为回复了OK的Server,如果一个之前为Leader的Server宣称自己不再是Leader,或者对其请求超时等等;则将保存的LeaderId设置为空,以确保下一轮Leader detection的进行。
Notify RPC Handler
Leader Server在收到来自Clerk的RPC请求之后会将对应的命令加入log中,并在备份成功之后进行commit。RPC Handler需要等待自己append的log entry被成功提交,或者是被删除(例如,新leader要求删除)时,才能回复Clerk。因此,一个问题是Handler如何知道自己append的entry是否被提交或者被删除了。
在Lab2的Raft中,apply一个entry是将其发送到一个ApplyMsg channel中,我们的KVServer需要不断读取该channel并将命令应用到本地kv中。一个自然的想法是,handler不断读取applier,通过index和term来查看是否是自己append的entry,然后执行对应的操作。
这个想法的问题在于一个RPC Handler可能读到另一个RPC Handler append的entry,此时除非其将读到的entry重新塞回applier中,否则另一个RPC Handler将永远读不到自己append的entry。但重新塞回这个操作可能导致无限循环:设想channle中有两个entry:a和b,分别由T1和T2处理。T1先读到b,然后将其塞回channel;T2接下来读到a,然后也将其塞回channel;接下来T1又将读到a,从而导致无限循环。
我们的处理方法是用一个数据结构专门保存已经apply的entry的index和term,然后让RPC Handler定期地去访问该结构,来查看自己append的entry是否已经被apply了,从而进行回复。
Duplicate apply
实验的Guidance提到可能会出现一个请求被重复apply的情况,例如:当一个leader成功apply了一个entry但还没有回复给Clerk时leadership转移给了另一个server,因此Clerk会再一次append该entry到新的leader。其结果就是Client只要求执行了一次Put/Append操作,但是效果却是执行了多次。对于非幂等的操作,例如本次实验中的Append操作,这种语义是不能接受的。
raft作者的博士论文的6.3节: “Implementing linearizable semantics”提到了该问题,并给出了解决方法,即使用Id唯一地标识每次请求,在apply时,如果发现一个request已经被处理了,就不要再将其应用到状态机上了。通过这种方法,可以确保每个request再每个server上至多只会执行一次。
在实验中,问题在于Id怎么设计。最初我们在Clerk中保存一个递增的SequenceNumber,每次请求都递增该值以获得一个Id。但是在test中,Clerk可能会被重启,从而导致该值被清空。对此,我们采用(ClerkId, sequenceNumber)的组合,每次重启Clerk时都适用一个新的ClerkId来区分之前的Clerk。
Request Timeout
如果一个RPC Handler执行的时间过长,需要将其打断以免导致无限循环。考虑在一个存在partition的网络中,一个raft leader被划分到了minority中。此时Clerk向该leader发起请求,能成功的调用Start,但是它却会一直因为该entry没能成功commit而阻塞。所以Clerk需要意识到这种情况,并尝试其他server。
小结
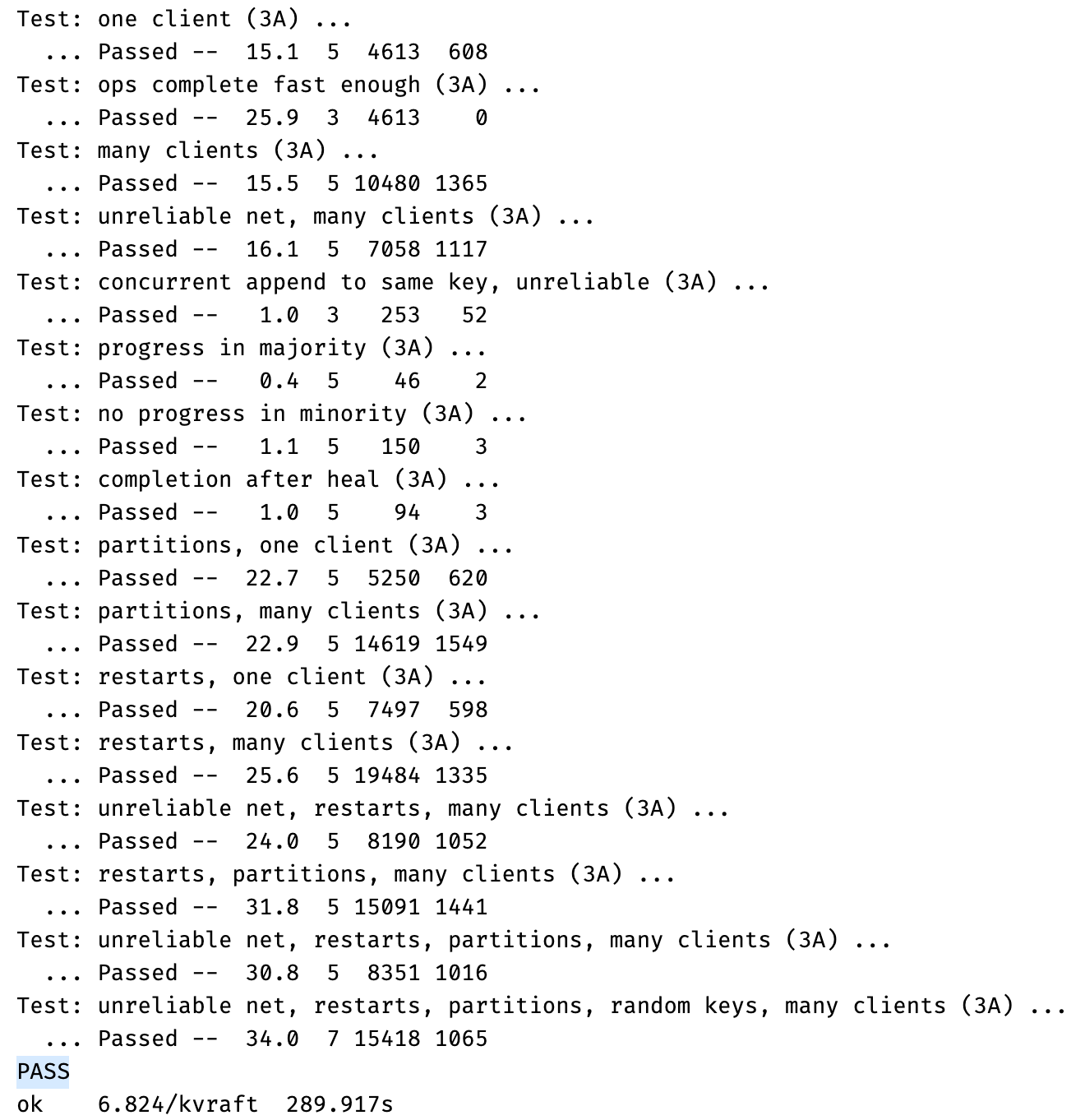
这个实验的原理比较简单,但是如上面所见,整个实验的细节较多,尤其是在如何notify handler的这个问题上,连着改变了好几次设计才最终通过测试。现在想想,应该是对Go不太熟悉导致的。最后放一张成功通过测试的截图: