
GFS Reading Notes
The Google File System
Pre-words
Before we started talking about GFS, we need to first talk about the basic design challenges of distributed systems. As professor Morris mentioned in this course, the relationship between a few basic factors of distrbuted systems can be expressed as follows:
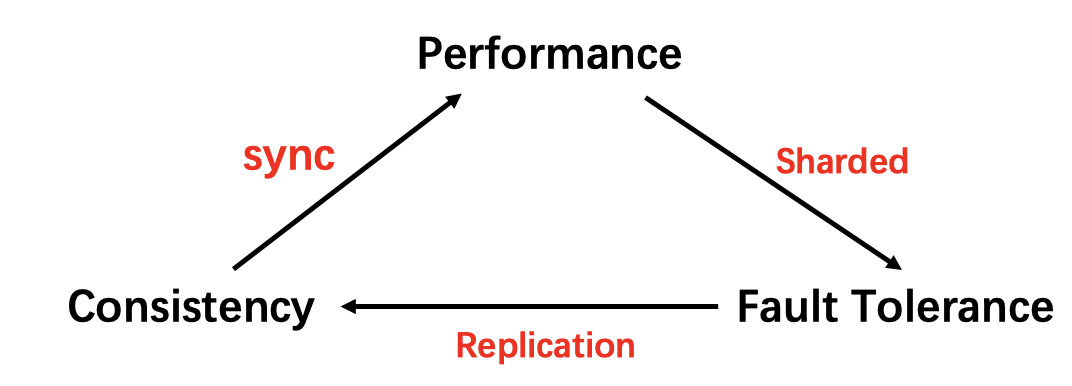 To achive better performance, the system use multiple server to gain parallel execution or storage. However, multiple servers may face constant failures and thus replication is necessary for the purpose of fault tolerance. There might be inconsistence between multiple replication of one single object, thus extra synchronization is needed to maintain consistence, which in turn degrades performance
To achive better performance, the system use multiple server to gain parallel execution or storage. However, multiple servers may face constant failures and thus replication is necessary for the purpose of fault tolerance. There might be inconsistence between multiple replication of one single object, thus extra synchronization is needed to maintain consistence, which in turn degrades performance
These relationships requires designer to take some trade-offs of distributed systems, e.g One may provide weaker consistency to achive better performance. Though much different, this “triangular” seems similar to the so-called “CAP Theorem“, which asserts one distributed system can not achive “C” (Consistency), “A” (Avaliability), “P” (Partition tolerance) at the same time. You may search it on Google for more information.
This GFS paper is a good example of distributed system practice in real world. It also faces the same problem as we stated above: inconsistency, fault tolerance, etc. We will see how GFS solves these problems by involving reasonable trade-offs, making it successful during last decades.
Overview
GFS (Google File System) is a distributed file system only for internal use in Google. The design assumptions of GFS are as follows:
- GFS is constructed on cluster comprising thousands of cheap commodity machines.
- GFS will typically support large files, say a few gigabytes.
- The workload of GFS:
- Read: Large streaming read & Small random read
- Write: Almost large sequential append opeartion, some random small write at specified offset
- GFS has to provide consistency guarantee for concurrent operation.
- GFS aims to provide high throughput, instead of low latency.
Considering the 2nd, 3rd and 5th requirements, one typical solution is to sharding one single file into multiple components and distribute them among different servers, in order to achive parallel reading or writing.
To maintain the filesystem metadata and execute operation logic, one monitoring machine is always needed. In some systems, this monitor machine is responsible for parsing request and all following work, including communicating with server storing file data and dealing with any exception. Monitor machine often becomes a bottleneck in such system as a result. However, GFS does not do it in the same way.
System Design
System structure
The overall structure of GFS is as follows:
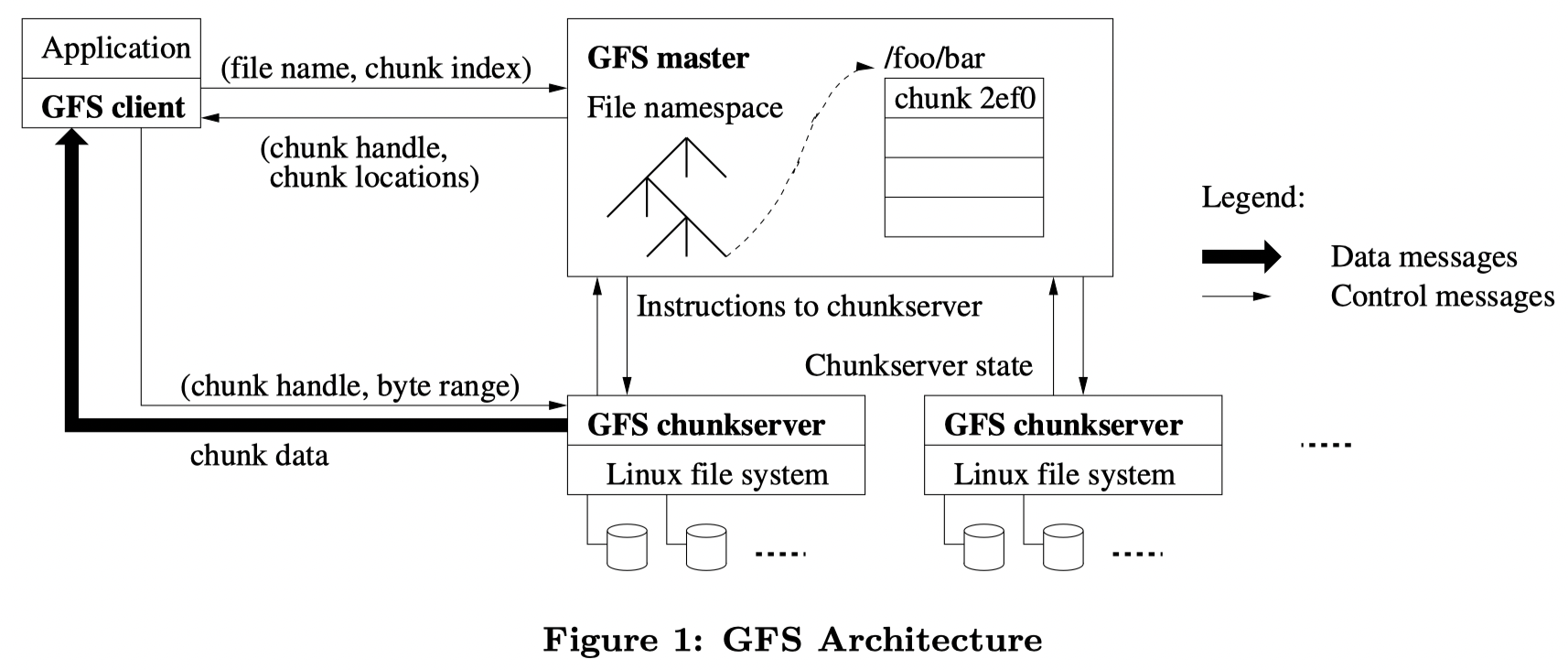
There are a few key points of GFS:
- There is a single master machine that maintains meta data of the whole file system, including file name and mapping table to corresponding chunk (talk about later).
- Each file is sharded into 64MB chunks and chunks are distributed among chunk servers in a form of Linux file. Each chunk has a few replications, the number is 3 by default.
- Master DOES NOT directly instruct chunk server to finish read/write operations, instead, the client does these work (See figure1, there are control messages from client to chunk server).
GFS operations
According to the paper, GFS does not provide standard POSIX file system interface such as mkdir, instead, GFS provides write, read, delete interfaces. All these interfaces are converted into single(or multiple) file write and read operations between chunk servers. So understanding single read/write opeartion is important.
Read
- The application calls GFS library with specified parameters, including Filename, Offset, Range.
- GFS library converts read range into Chunk Index, and send a request message carrying these parameters to master.
- Master replies with chunk server location and chunk handle. Since there are replication of one single chunk, the reply message is a list of chunk servers containing this chunk.
- Client directly read data from one chunk server. Typically client would read the nearest one.
Write
In GFS, there are sequential append write or small random write, but the process are generally the same. In write operation, one challenge is to maintain consistence between all replicas of a single chunk. GFS use primary-secondary method to solve this problem.
Primary replication
GFS periodically picks one replication as primary replication, the others are called secondary. The primary-secondary method ensures consistence by enforcing all secondary replicas execute writing in the same order as the primary one does. This guarantees all replications has the same content after one single write is successfully returned.
In case that primary failure causes chunk server pause to provide service, GFS master grants each primary with “Lease”. A lease is typically 60s duration in which primary deals with client write request. When the lease is over, master grants a chunk server(maybe this old server once again) with new lease.
Write process
- GFS master replies client with message telling locations of chunk servers containing specified chunk
- Client pushes all data to these chunk servers, and wait for their acknowledgement.
- Once written data has been pushed to all replication chunk servers, the client notifies primary server to execute write operation.
- Primary server execute write locally and notifies other secondary servers to do the same thing, wait until secondary servers reply.
- Primary replies to client with a success message if all secondary servers finish the operation, otherwise returns error.
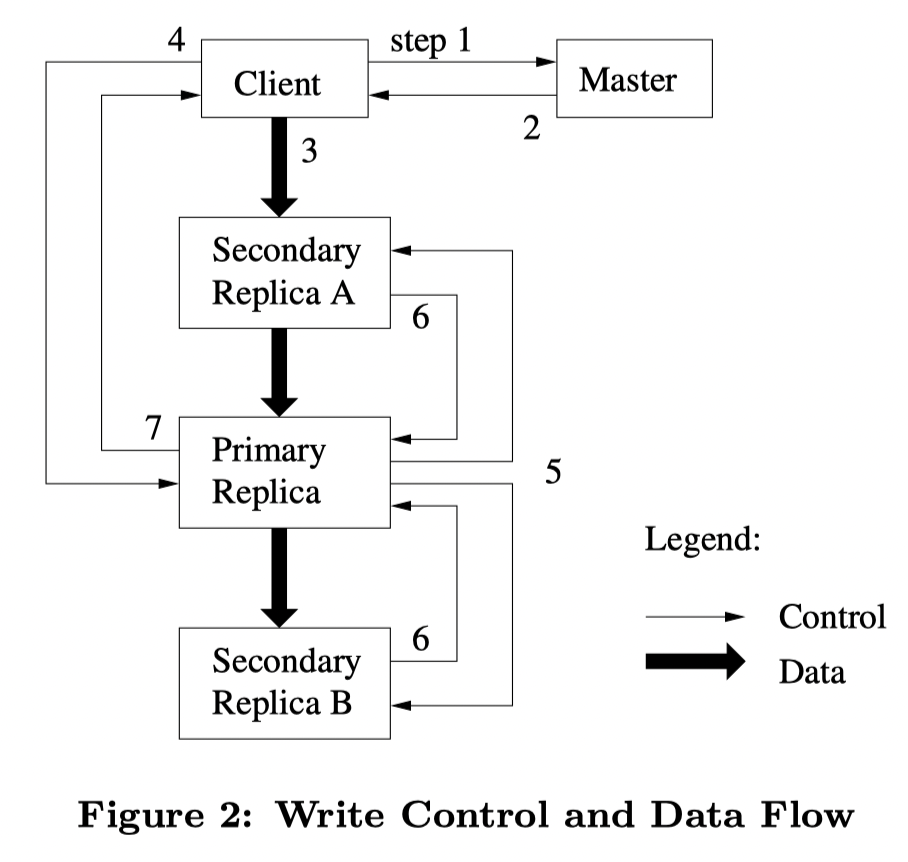
If one write operation is returned sucessfully, the reader is supposed to see the same contents no matter which chunk server it’s reading. However, if write fails, some chunk server may have fully executed write while others may not (They may also do it but reply message is lot due to network ), leaving chunk servers inconsistent.
Consistence
The GFS system defines two status of a chunk: consistent and Defined.
- A chunk is consistent, if a read operation always see the same data from any replication.
- A chunk is defined, if it is consistent and “clients will see what the mutation writes in its entirety.”
A consistent chunk means a write operation synchronized between primary and secondary replication, as we have discussed above, a successful write or append leaves a chunk consistent, and also defined. A fail write may leave this chunk inconsistent. These are all cases of single client and sequential access, what about concurrent write?
Other details
Master Data and Operation
Data
The master is a central point of the whole system, it contains the following meta data:
- File system namespace, including all created file and associated information.
- A mapping table records the location of servers containing each chunk.
- Log array that records each mutation to the file system.
According to Figure1, we believe that all files are structured into a tree for fast indexing.
Also, we have to consider master failure. To recover from server failure, some data has to be non-volatile, including: File system namespace and Log array. The Mapping table does not necessarily have to be non-volatile, since master will quries each chunk server the chunks it has during start-up.
Operations
Periodically Pingpong
The master server has to periodically send heartbeat messages to chunk servers in case that some replications are lost.
File system namespace management
Master has to manage file system namespace, e.g Create file or delete file, updating mapping table. This is basically a single machine concurrent problem. GFS uses directory locking scheme to support concurrently access and manipulations to namespace.
When accessing a file, it acquires read or write lock in the file system hierarchy “tree” from top to bottom. For example, when accessing /usr/foo/bar, the master acquires read lock on /usr, /usr/foo, /usr/foo/bar sequentially.
Replica replacement, gabage collection
Master has to deal with replica replacement in order to achive high bandwidth and fault tolerance. The paper describes a few principles:
- Distribute the replica of a single chunk across racks (What does rack mean?)
- Place replica on servers with below-average disk space utilizations
- Avoid placing replica on servers that has many newly-created replicas, because create replica may mean heavy write or read workload on this server.





