
Percolator: Google's transactional system
Percolator: Google’s transactional system
Overview
本文介绍Google的上一代分布式事务系统:Percolator。Percolator首次出现在Google于2010年OSDI发表的论文:Large-scale Incremental Processing Using Distributed Transactions and Notifications 中。Google基于BigTable提供的单行事务语义实现了一个跨行,跨表的事务系统,称为Percolator,该系统基于2PC,支持Snapshot Isolation的隔离级别。TiDB在事务方面的实现也是基于Percolator模型,但是进行了一些优化,例如增加了悲观锁和Async commit。
Background & Motivation
在21世纪的第一个十年,Google陆续发表了GFS, BigTable, MapReduce, Spanner等系统用以支持各种大数据应用。Percolator也是在这样的背景下诞生的,正如论文原文的描述:
Within Google, the primary application of Percolator is preparing web pages for inclusion in the live web search index
Percolator最初的作用是用于搜索引擎中网页链接的更新等操作。这些操作类似于OLTP负载,每次只需要对部分较少的数据进行操作。MapReduce系统可以用于执行批处理任务,但是对OLTP型任务支持较差,除非你愿意只为了更新一小部分数据而扫描所有的数据;传统的关系型数据库可以胜任OLTP任务,但是Google的网页数据分布在数千台机器上,而传统的分布式数据库还难以达到这样的扩展性。具有很好的扩展性,并且提供简单的存储接口的BigTable被认为是执行这类任务的一个较好选择。因此,Google考虑在BigTable的基础上实现ACID特性的事务支持(为了方便程序员编程),即Percolator系统。
BigTable是Google开发的一个结构化的键值存储系统,详细设计可以参考Google于2006年OSDI发表的论文: Bigtable: A Distributed Storage System for Structured Data。BigTable本身已经支持了单行的事务,也就是:对于同一行的数据修改访问能够以事务的方式执行。Percolator在BigTable的基础上支持了跨行的事务,为编程人员提供了更加方便的接口。
Snapshot Isolation
Percolator实现了Snapshot Isolation[1], 简单来说,就是一个transaction能访问到的数据就好像在这个transaction开始之前的某个时刻的一个snapshot一样。而这个transaction对数据库所做的修改只是在这个snapshot上做修改,直到最后commit这个transaction时才能使修改对外界可见。
Snapshot Isolation或许是MVCC的一个自然结果,它没有Serializable Isolation那么强的隔离性,因此在性能上有一定的优势。BigTable本身已经支持多版本的数据访问,这使得Percolator实现Snapshot Isolation相对简单。
在Snapshot Isolation中,一个transaction的执行需要经过以下步骤:
- Transaction开始时获取一个单调递增的时间戳,称为start_ts;Transaction读取任意一个时间在start_ts之前的数据库快照。
- Transation在这个快照上对数据库进行修改或访问。
- 当Transaction需要提交时,它获取一个时间戳,被称为commit_ts, commit_ts需要比start_ts和任何commit_ts都要大。Transaction会检查自己的write set中是否有与其他transaction冲突的,如果没有,则apply自己的修改到database中,即commit;否则当前transaciton abort。
上述算法中的一个问题在于如何检测write set是否与其他某个transaction的write set冲突。一个简单的实现方法是对write set中的每个record上锁,同时用一个map来记录每个record最后被修改的transaction的timestamp,然后检查这个timestamp是否在区间[start_ts, commit_ts]中。
实际上,将上述算法直接实现在BigTable里面就可以实现SI,但是这里有一些实现上的细节问题:
- 上述算法需要一个Lock Manager, 而在分布式系统中实现一个全局的Lock Manager很困难。事实上,HBase在实现Snapshot Isolation的方案中使用了这种办法,HBase-SI将Lock和CommitTimeStamp存储在另一张表中,作为中心化结构。
- 如果采用锁的方案,如何避免死锁。这回到了上一个问题,如果有一个全局的Lock Manager,可以采用死锁检测的方式来打破死锁,但如果没有这样的中心化结构又该如何处理?
- BigTable不是单机结构,在分布式系统中如何保证事务的ACID特性?一些已有的算法应该能派上用场,如2PC。
Percolator Design
Overview
Percolator的commit算法类似于2PC, 整个transaction在执行时先将修改操作缓存在client本地。在client发起commit请求时,执行2PC。commit过程分为两个阶段:prewrite和commit。其中prewrite会锁住要修改的行,然后将之前缓存的修改操作写入BigTable中,用一个特定版本号标识;commit会写类似于之前提到的commit log的数据,来确保prewrite中写入的数据对外界可见。只有在所有prewrite操作都成功时,commit操作才会执行,因此是两阶段的。
Transactional Semantics
Percolator实现了Snapshot Isolation的隔离级别。Transaction只能读取start_ts(小于等于)之前的数据。对于修改操作,数据被先缓存到client本地,因此在事务被成功commit之前不会对数据库产生实际的修改。一个问题是如果一个transaction内部需要对同一个transaction内刚刚修改了的数据进行访问,那么读结果应该返回新结果还是旧结果?从论文提供的伪代码来看,会返回旧结果;但是按理说应该返回新结果比较合理。
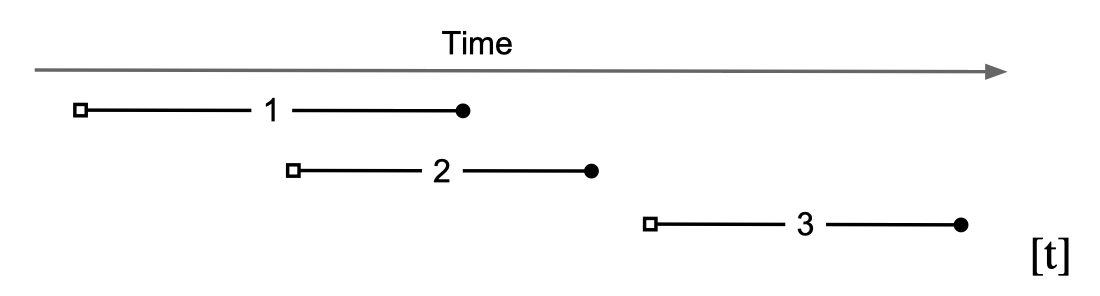
上图的白点代表start_ts, 黑点代表commit_ts。Percolator保证一个transaction只能读到commit_ts小于等于它的start_ts的transaction提交的结果。
Transaction Execution
Additional Metadata
Percolator实现在BigTable的基础之上,它实现了一套非侵入式的接口。也就是,在不修改BigTable内部实现的基础上,利用BigTable提供的单行事务和多版本机制来实现Percolator事务处理。为此,Percolator增加了如下的一些额外元数据:

其中值得关注的是lock和write列,data列是将原先的BigTable所存储的所有数据抽象为一个整体的column。lock列是一个用于并发控制的列,如果某一行正在被一个事务修改(指的是在prewrite阶段),那么就给这行上锁,来避免被并发的事务修改;write列用于记录commit log, 也就是最近已经提交的修改了该行的transaction的id(id也就是timestamp,因为不同事务的start_ts和commit_ts不同,所以可以唯一标识一个txn)。
Execution Process
Transaction start
一个事务由client发起,发起的方式是创建一个Transaction结构体,在创建这个结构体时,会首先从TSO(TimeStamp Oracle)中获取一个时间,称为start_ts,代表这个事务开始的时间。原论文中给出了一些实现伪代码,所以这里会结合伪代码来说明。(不得不说Google的论文这一点做的很好,结合代码可以让很多算法和概念变得容易理解)
class Transaction {
public:
struct Write {
Row row;
Column col;
string value;
};
vector<Write> writes_;
int start_ts_;
Transaction(): start_ts_(oracle.GetTimestamp()){}
};Transaction execution
事务执行包括Get和Set两个操作,前者从数据库的startts之前的snapshot中获得数据,后者修改某个指定的行和列的数据。正如前面所说,Set操作并不会立刻修改BigTable,而是先被client缓存:
void Transaction::Set(Write write) {
writes_.push_back(write);
}Get操作会从数据库中获取数据,但是只获取那些修改发生在start_ts_之前的数据。这里可以直接使用BigTable提供的多版本机制来读取verion小于start_ts_的数据,另一个值得注意的问题是如果当前读取的行有一个lock怎么办,由于读操作读的是之前的版本,所以检查lock时也是检查之前版本的lock, 如果有这么一个lock,那么说明之前的某个事务还没有提交,或者提交了但是没有来得及清理lock。当前执行的事务可能需要回退等待事务提交,或者清除这个failed transaction留下的lock。
bool Transaction::Get(Row row, Column c, string* value) {
while(true) {
bigtable::Txn T = bigtable::StartRowTransaction(row);
if (T.Read(row, c+"lock", [0, start_ts_])) {
BackoffAndMaybeCleanLock(row, c);
continue;
}
latest_write = T.Read(row, c+"write", [0, start_ts_]);
if (!latest_write.found()) { // No data for this cell
return false;
}
int data_ts = latest_write.start_timestamp();
*value = T.Read(row, c+"data", [data_ts, data_ts]);
return true;
}
}接下来,Get操作会查看这个cell(row + column)是否有已经提交了的数据(通过查看write列,也就是commit log), 如果有,那么读取最近一个commit log的start_ts, 它的数据就是我们要读的数据。
这里的Get操作保证了Transaction Semantics一节中的语义:Get操作只会读取那些在start_ts之前被提交的数据,这里的write列中的数据形式如下:commit_ts: start_ts, 其中commit_ts是BigTable中的版本号,start_ts是BigTable中存储的数据,在后面会讲,commit_ts就是一个事务提交的时间戳,因此T.Read(row, c+"write", [0, start_ts_])就是在读一个事务的开始时间,这个事务的版本号<=start_ts_,即这个事务的提交时间晚于start_ts_。而这个事务在数据库中的版本是由start_ts_唯一确定的。
Transaction commit
Prewrite
Percolator的事务提交采用了2PC的方式,所有在Client端缓存的修改先通过Prewrite写到数据库中,如果有任何一个写入失败那么事务将abort;如果所有预写成功,client会修改write列,来使得事务的修改对其他事务可见。
(说这个过程是2PC其实我不太理解,因为我并没有看到它和分布式事务有什么关系,一切都是在BigTable已经提供的单行分布式事务抽象下执行的,所以我更愿意将其理解为一个单机的2PC; 还是说一切由两个阶段组成的commit过程,无论单机还是分布式,都叫2PC?)
对于事务提交,Percolator会在这个事务的所有修改中选择一个,称为Primary,作为整个事务的互斥点。所谓互斥点的意思就是,如果这个修改对应的行被提交了(指它的write列被对应修改了),那么就认为这个事务已经提交了。否则,这个事务没有提交。这样设计的目的是解决故障问题,如果一个事务的client crash了,那么它crash只会导致两种结果,要么这个txn的primary被提交了;要么没被提交。后续的transaction可以根据这两种分支来做相应的处理。
bool Transaction::Prewrite(Write w, Write primary) {
Column c = w.col;
bigtable::Txn T = bigtable::StartRowTransaction(w.row);
if (T.Read(w.row, c+"write", [start_ts_, inf])) {
return false;
}
if (T.Read(w.row, c+"lock", [0, inf])) {
return false;
}
T.Write(w.row, c+"data", start_ts_, w.value);
T.Write(w.row, c+"lock", start_ts_, {primary.row, primary.col});
return T.Commit();
}上述代码描述了对一个Write操作执行prewrite的过程,prewrite是对一行执行read-modify-update的过程,因此可以使用BigTable提供的行级事务来确保正确性。
正如前面在Snapshot Isolation一节描述的,prewrite检查冲突是否发生:
- 是否有一个transaction已经提交了(第4行),这个transaction的commit_ts大于当前事务的start_ts, 说明二者在时间上有交集,又因为二者同时修改了同一个行,所以空间上有交集。根据SI的要求,两个冲突的事务只能有一个能成功,所以当前事务必须abort。
- 检查当前的行是否已经被上锁。这里的本意应当是避免两个事务同时修改一个行,但是这里检查的范围是
[0, inf],也就是之前事务遗留的锁也可能导致当前事务abort。对此,我的解释只能是在之前系统已经清除了所有遗留lock。
当完成上述检查之后,当前事务将修改应用到BigTable中。这里写了lock列,如果这个write是primary的,那么lock列的内容可能是一个PRIMARY LOCK标志之类的东西;否则secondary的write会在这个列写下primary lock的指针。当后续因为client crash,新的transaction需要清理lock时,可以通过这个指针找到当时事务的primary write,从而确定当时事务的状态。
Apply & make visible(commit)
当调用Transaction::Commit时,用户将这个事务进行提交,这个函数内部分为两个阶段:首先对所有write执行prewrite,通过后再正式提交:
bool Transaction::Commit() {
// Phase1: Prewrite all write
Write primary = writes_[0];
vector<Write> secondaries(writes_.begin()+1, writes_.end());
if (!Prewrite(primary, primary)) {
return false;
}
for (write : writes_) {
if (!Prewrite(write, primary)) {
return false;
}
}
// Phase2: Make the modification visable
int commit_ts = oracle_.GetTimeStamp();
Write p = priamry;
bigtable::Txn T = bigtable::StartRowTransaction(p.row);
if (!T.Read(p.row, p.col+"lock", [start_ts_, start_ts_])) {
return false;
}
T.Write(p.row, p.col + "write", commit_ts, start_ts_);
T.Erase(p.row, p.col + "lock", commit_ts);
if (!T.Commit()) {
return false;
}
for (Write w : secondaries) {
bigtable::Write(w.row, w.col+"write",commit_ts, start_ts_);
bigtable::Erase(w.row, w.col+"lock",commit ts);
}
return true;
}当一个Transaction的primary write被commit之后,这个事务就被认为已经提交了,所以在commit时primary write是首先被提交的。值得注意的是在18行,在primary write被提交时需要先检查lock是否还存在,这里让我比较疑惑的是在什么情况下这个lock会被清除。因为第5行的Prewrite(primary, primary)如果成功,那么lock列一定是被写入了数据的,可能是有另一个并发的事务清除了这里的lock?
Failed Transactions
一些事务可能因为Client的崩溃导致执行到一半就没能进行下去,因此会在BigTable中留下不完整的状态。判断一个事务是否成功commit的标准是这个事务的primary事务是否被提交,如果被提交那么这个事务就认为被提交了。
当后续事务访问BigTable时可能会遇到一些残留的lock,它们需要决定是roll forward还是roll back。通过读取这些lock指向的primary write lock,它们可以决定crash的transaction是否已经commit。
Reference
[1] Berenson H, Bernstein P, Gray J, et al. A critique of ANSI SQL isolation levels[C]//ACM SIGMOD Record. ACM, 1995, 24(2): 1-10.
[2] Zhang C, De Sterck H. Hbasesi: Multi-row distributed transactions with global strong snapshot isolation on clouds[J]. Scalable Computing: Practice and Experience, 2011, 12(2): 209-226.




